-
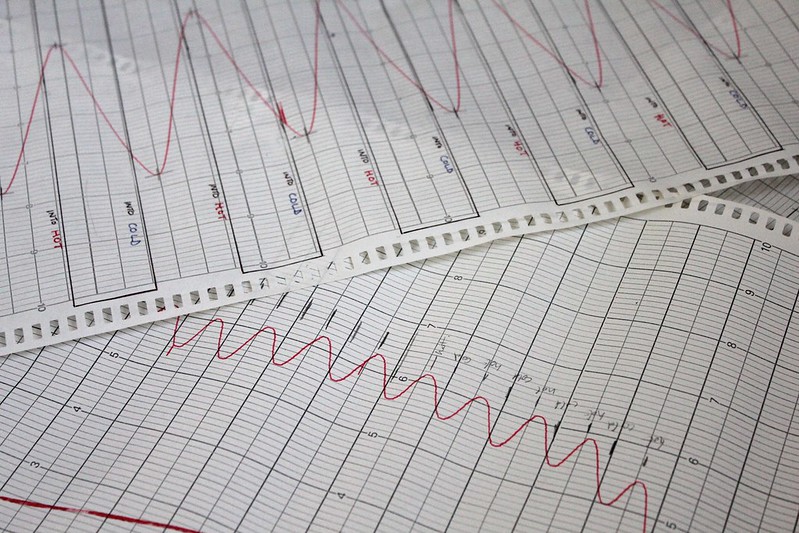
Druid Sneak Peek: Timeseries Interpolation
Apr 8, 2023 • blog, apache, druid, imply, iot, sql, tutorial
-
Druid 26 Sneak Peek: Window Functions

-
Selective Bulk Upserts in Apache Druid
Mar 7, 2023 • blog, druid, imply, adtech, tutorial, update, crud
Apache Druid is designed for high query speed. The data segments that make up a Druid datasource (think: table) are generally immutable: You do not update or replace individual rows of data; however you can replace an entire segment with a new version of itself.
-
Streaming Events from Redpanda Cloud into Imply Polaris
Feb 14, 2023 • blog, druid, imply, polaris, saas, eventstreaming, redpanda, kafka
-
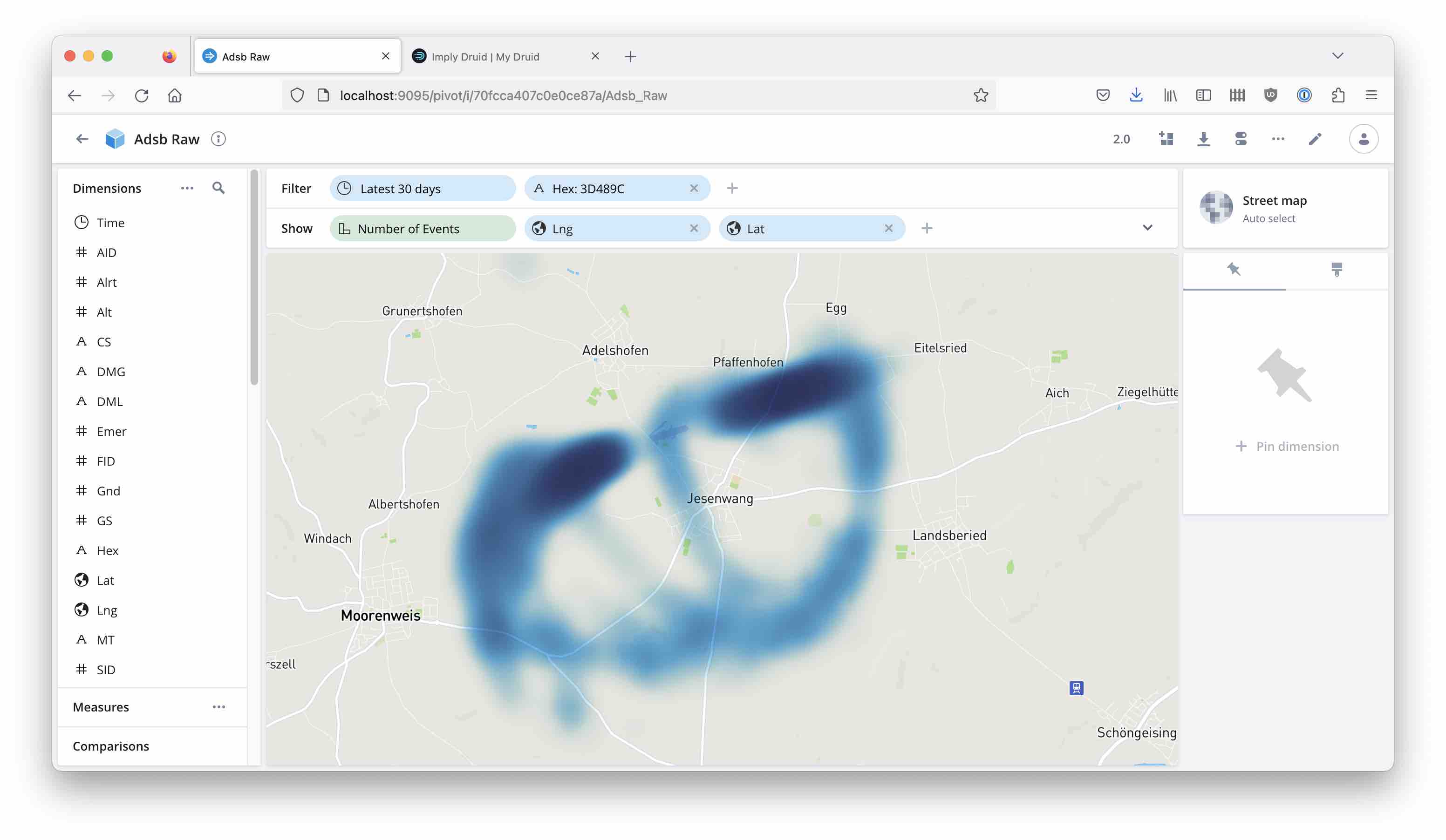
Street Level Maps in Imply Pivot with Flight Data and Confluent Cloud
Feb 1, 2023 • blog, druid, imply, pivot, confluent, kafka, tutorial
-
Druid Sneak Peek: Timeseries Interpolation
-
Druid 26 Sneak Peek: Window Functions
-
Selective Bulk Upserts in Apache Druid
Apache Druid is designed for high query speed. The data segments that make up a Druid datasource (think: table) are generally immutable: You do not update or replace individual rows of data; however you can replace an entire segment with a new version of itself.
-
Streaming Events from Redpanda Cloud into Imply Polaris
-
Street Level Maps in Imply Pivot with Flight Data and Confluent Cloud