Streaming Events from Confluent Cloud into Imply Polaris using Nifi
Imply Polaris is a fully managed database-as-a-service (DBaaS) based on Druid. It has been designed to give a hassle free experience of blazing fast OLAP, without bothering about the technical details.
One of the strengths of Druid is the ability to ingest and analyze event data in near real time, encapsulating what we used to call a Kappa Architecture in the Big Data hype period. Polaris supports this paradigm by exposing an Event Streaming REST API. But how would we connect an event stream that exists in, say, Kafka, to Polaris today?
For today’s tutorial I have set up a topic in Confluent Cloud, which generates quite a lot of simulated clickstream data.
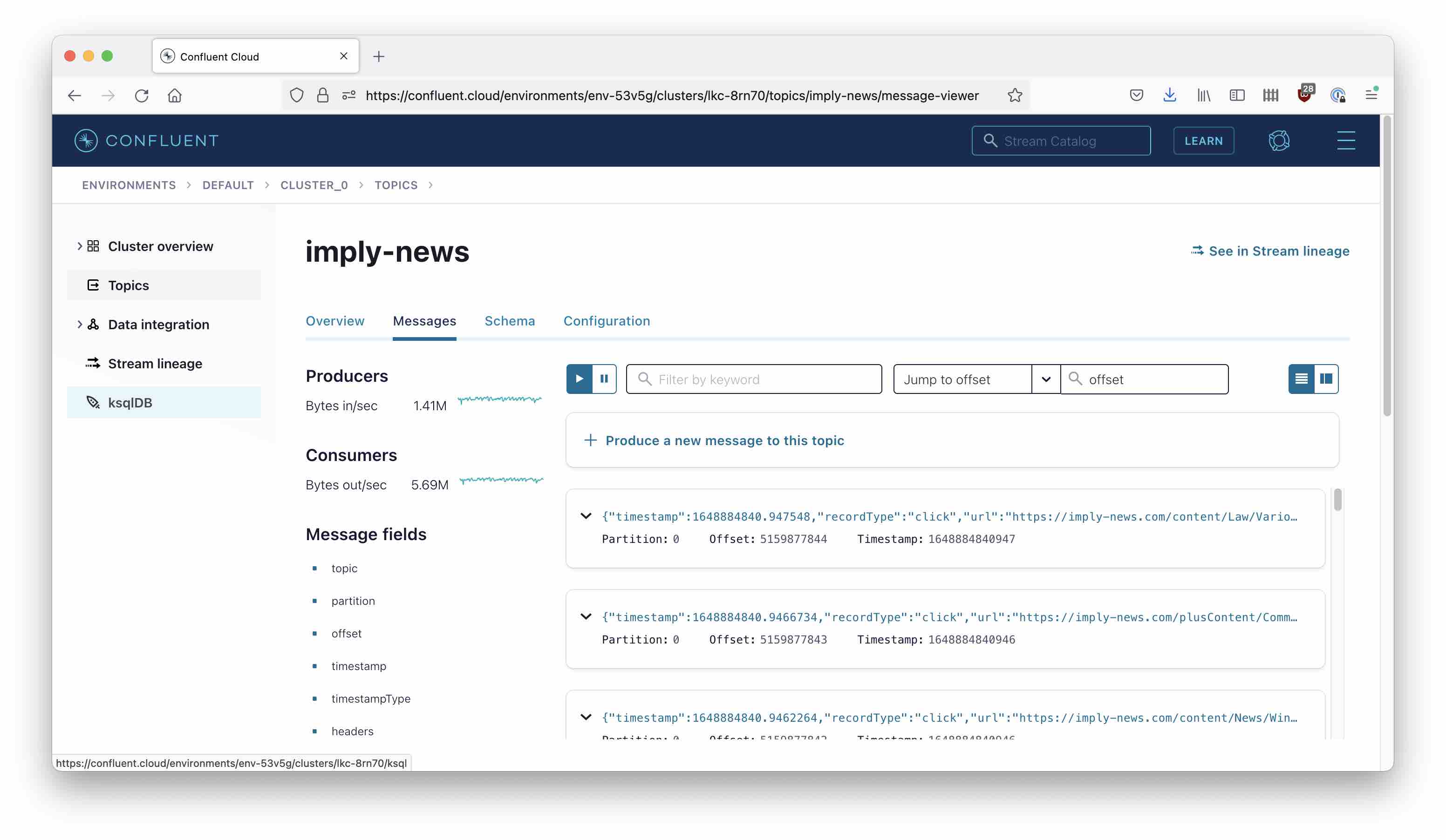
The data has a field called timestamp which is in seconds since Epoch, so some transformation will be needed. What we have to do:
- Read data out of Confluent Cloud
- Batch events up to a convenient size (not too small but less than 1 MB)
- Rename the timestamp field to
__timeand transform it to either ISO format or milliseconds since Epoch, according to the Polaris requirements - Apply some filtering because my topic might spew out more data than we can handle
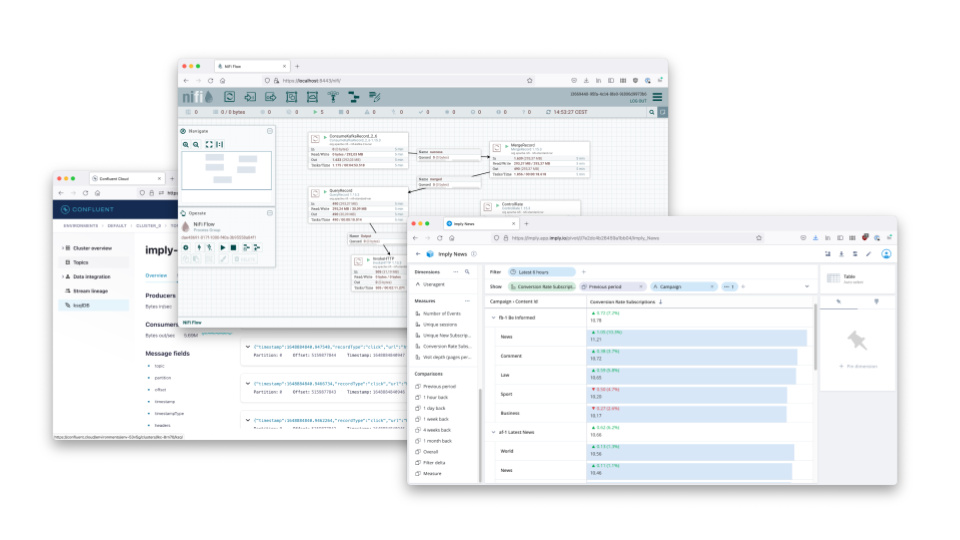
A great tool to perform all these tasks is Apache NiFi, the Swiss Army knife of streaming data integration. Today I am going to show you how to build a flow like this:
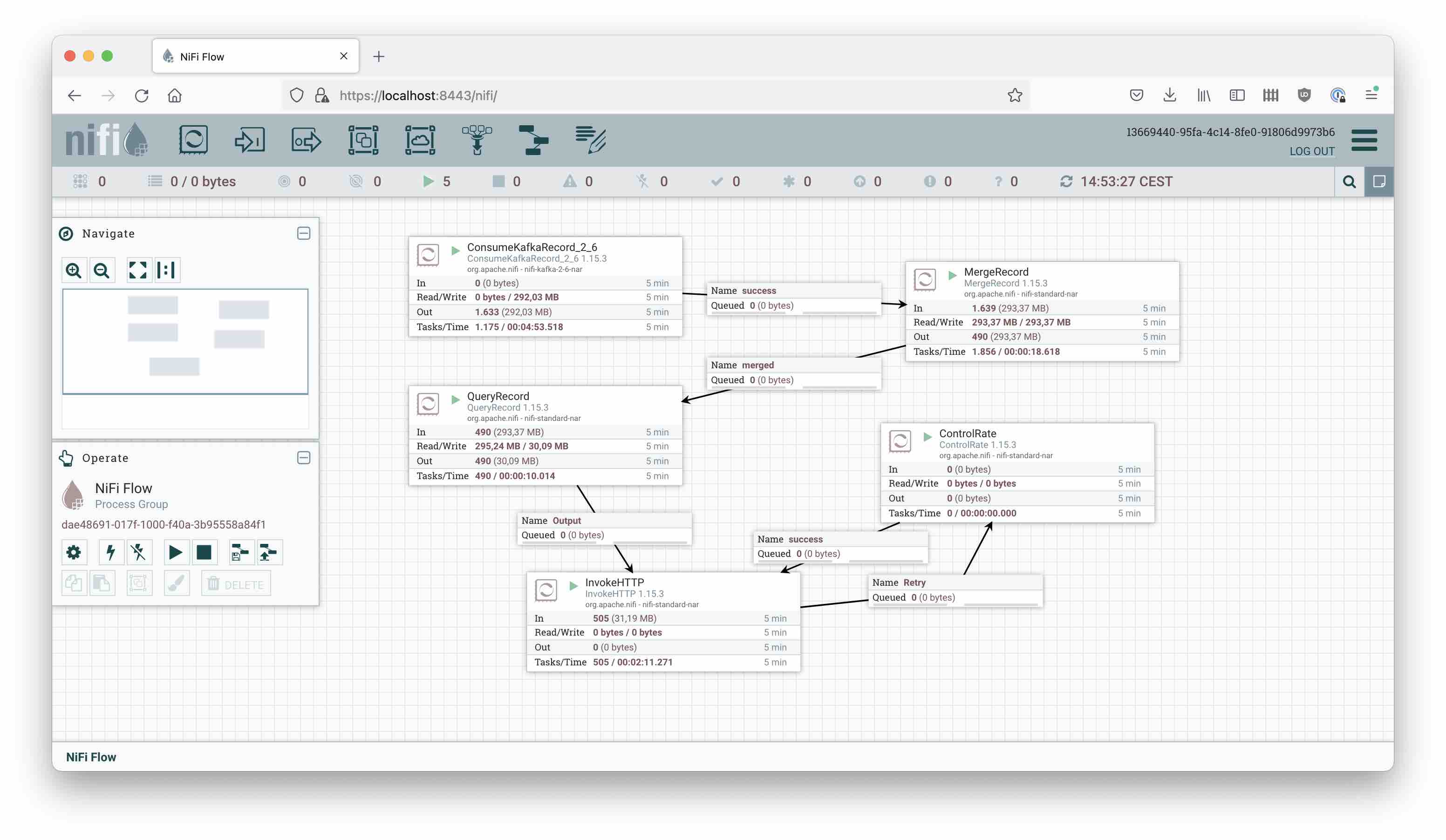
Let’s get to work!
Prerequisites
Preparing the Polaris Table
First of all, we are going to need a target table in Polaris. The best way to create this table is to take a sample of the topic data, save it into a file and upload this file to Polaris. Create a schema and ingest the sample according to these steps. Once you have the table ready, go to the table detail page and obtain the endpoint for the Push Event API:
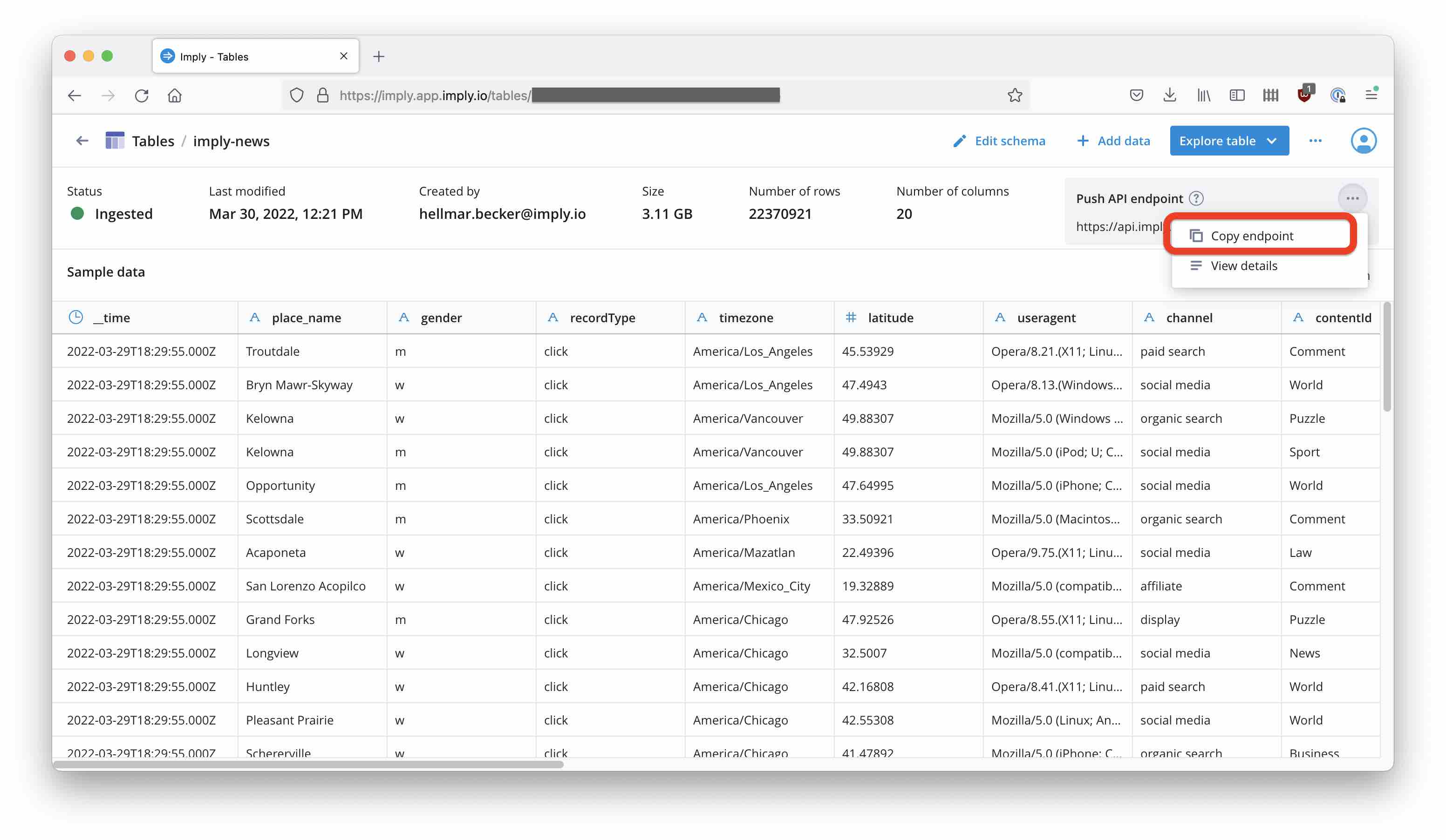
Note this down - we will need it later.
Also, create an API client and token that we will use for authentication against Polaris. Make sure to extend the token’s lifespan to 1 year.
You can download the API token in the API Client GUI of Polaris:
Preparing Confluent Cloud
You will also need:
- you Kafka endpoint URL (Broker URL) from Confluent Cloud
- a service account that will have access to your Kafka topic
- a Kafka API key and secret associated with that service account
- a consumer group ID that you can choose freely, but …
- you need to create an ACL for your consumer group in Confluent Cloud to give your service account read access to that consumer group.
I’ve covered this in a bit more detail in my post about Confluent Cloud integration with Druid.
Components of the NiFi Flow
Controller Services
I am using Nifi 1.15.3 for this tutorial, and I am going to make use of Record processors. Each Record processor needs a Record Reader and a Record Writer. Since we are going to read whatever JSON we get at every stage, the Record Reader is generally just going to be a JsonTreeReader with the default configuration.
For the Record Writer, consider that Polaris expects data to arrive in ndjson format (1 JSON object per line). This is conveniently achieved using a JsonRecordSetWriter, by setting the Output Grouping attribute to One Line Per Object:
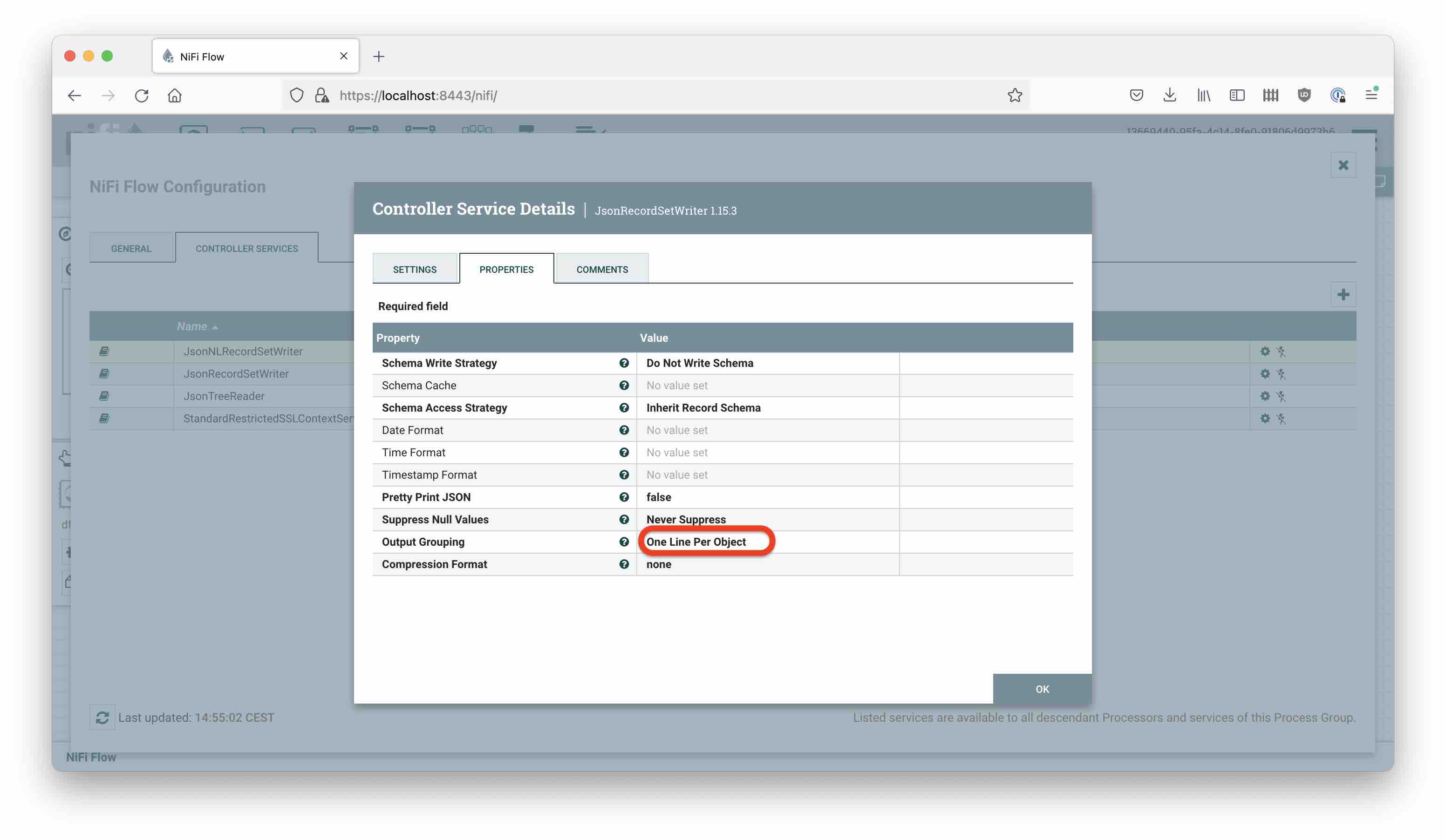
If you don’t do this, the output will be a JSON array and Polaris will not be happy.
Kafka Consumer
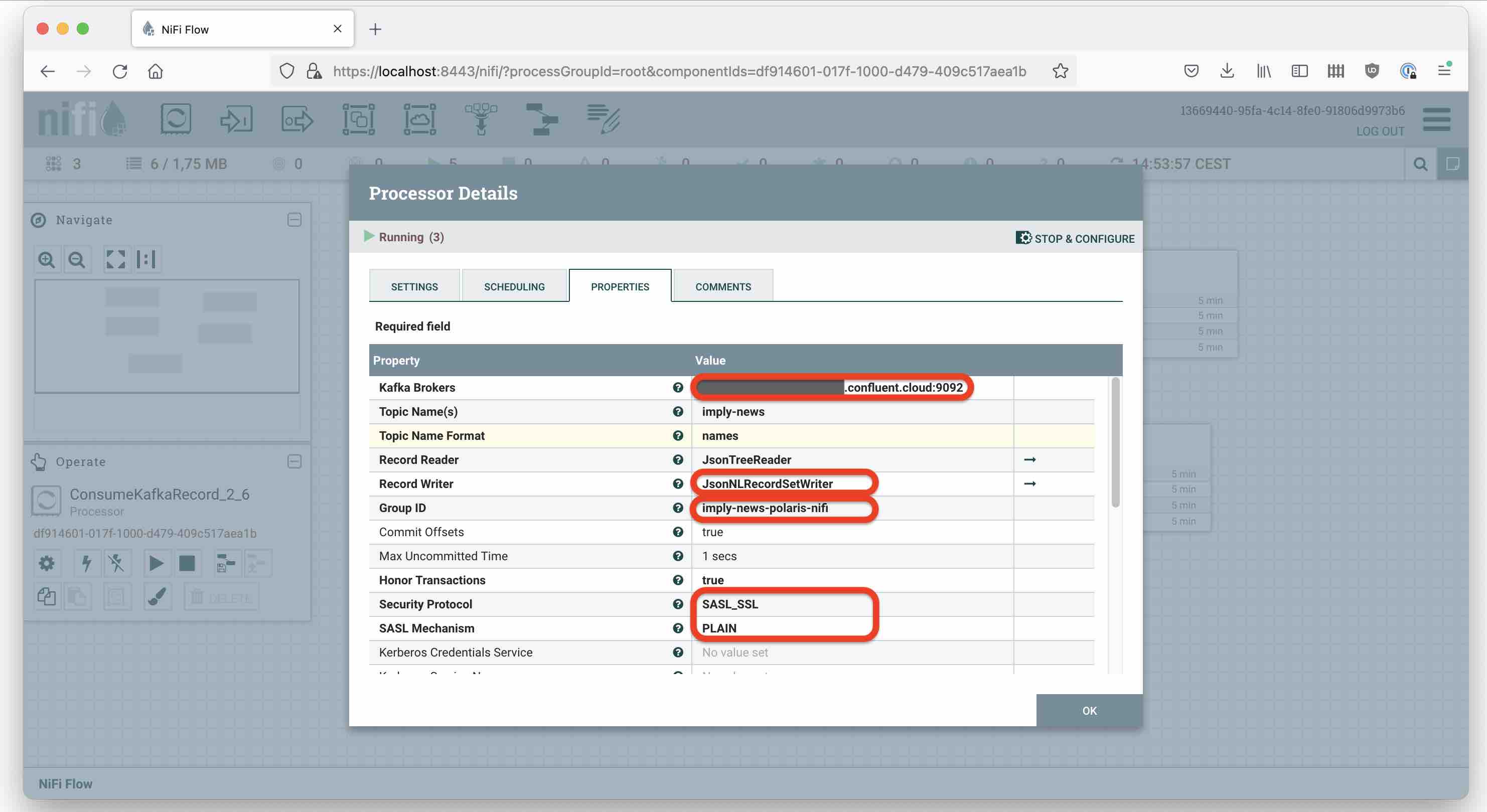
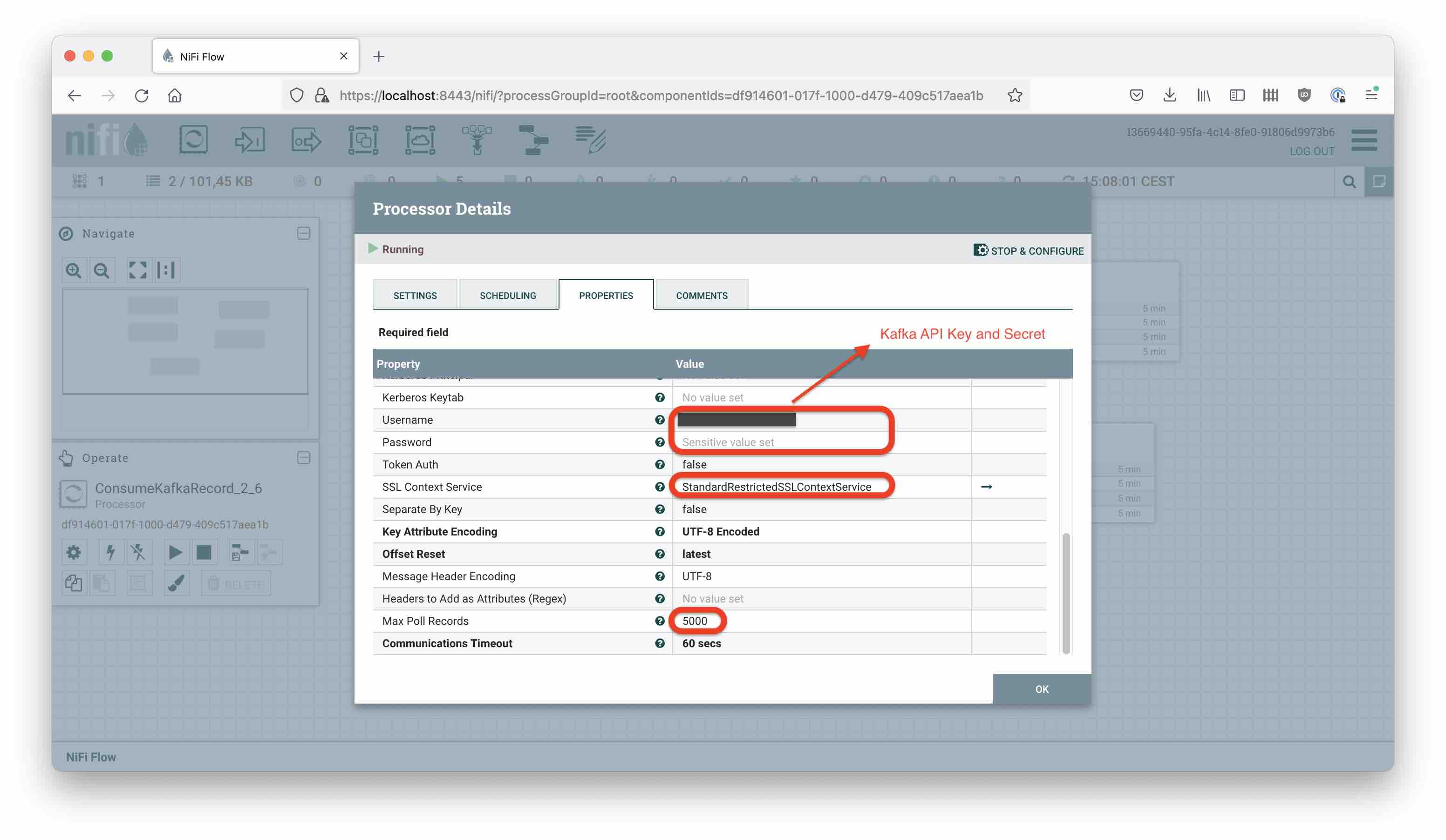
You need to set:
- the broker URL
- the Record Reader and Writer (see above)
- the Consumer Group ID (the one you picked earlier)
- the security protocol (
SASL_SSL/PLAIN) - username and password are your Kafka API key and secret
- SSL Context Service, create one pointing to the truststore of your JVM (format is JKS and password is “changeit”)
- Max Poll records, estimate it such that you don’t consume more than 1 MB in one go
Here are my settings:
Auto-terminate all relationships except success, which will go on into the merge processor.
Merge Records
We want to batch up data for scalability, so let’s insert a MergeRecord processor:
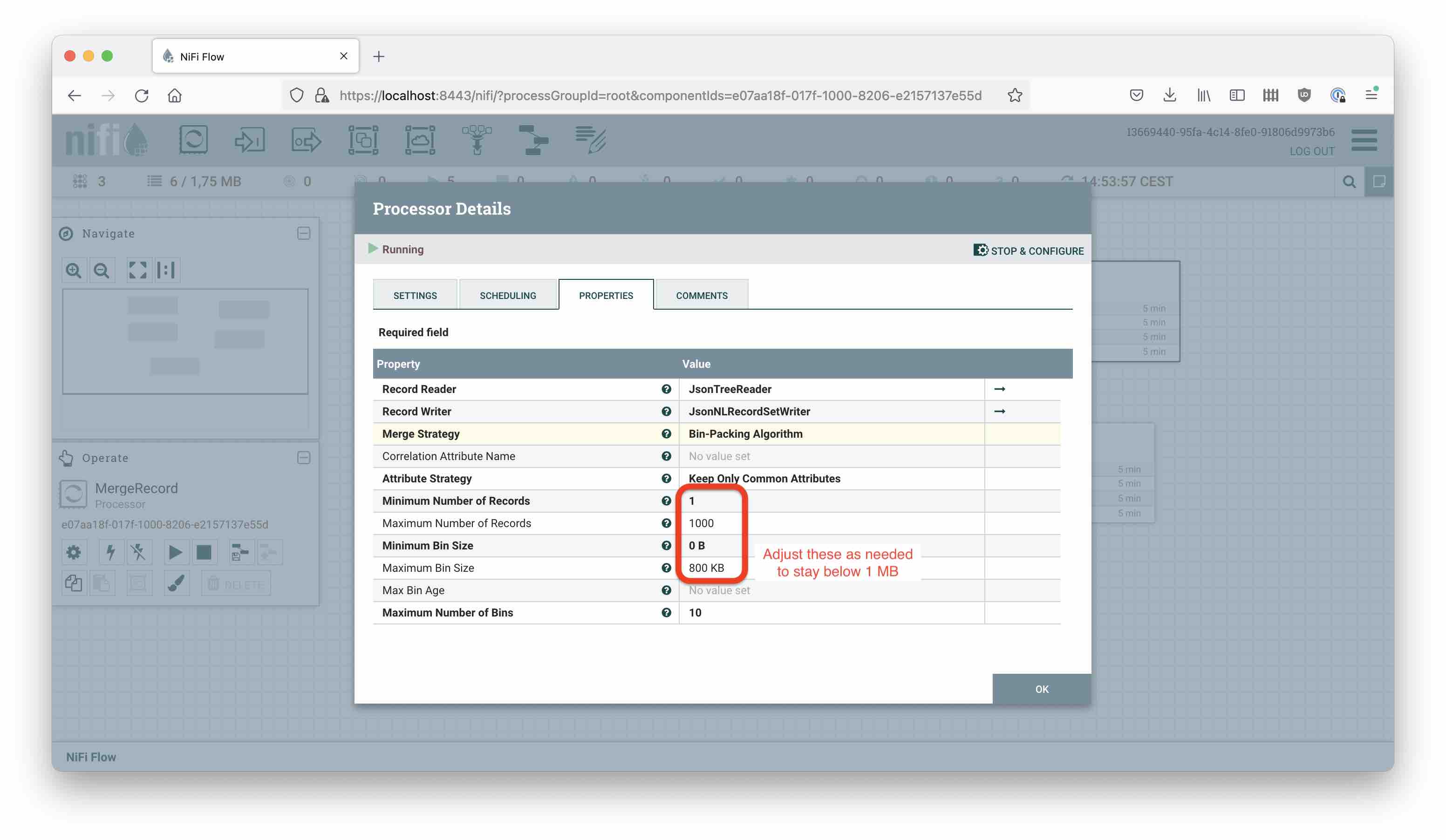
Transform
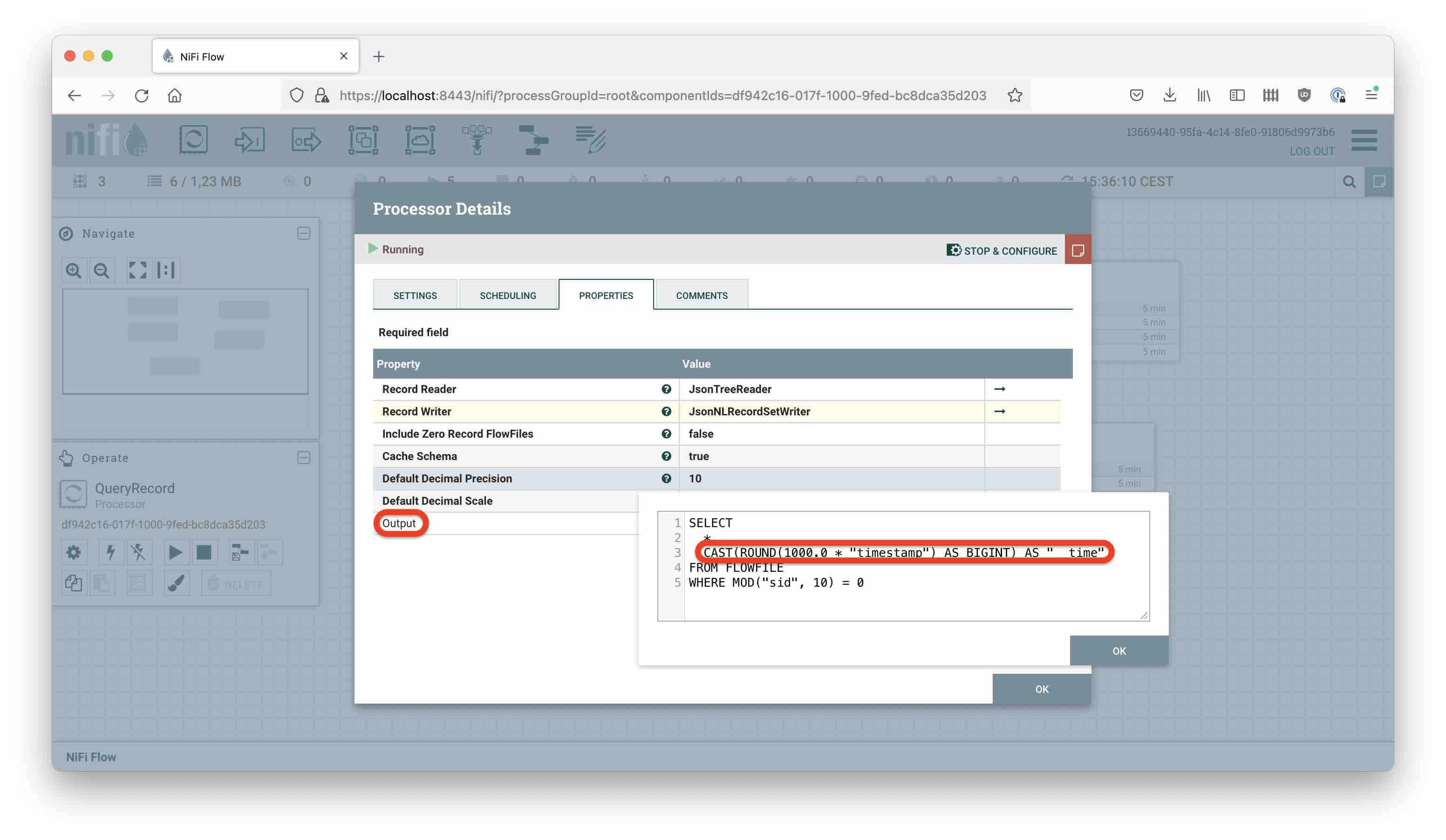
We are going to use a QueryRecord processor to transform our JSON data using SQL. This achieves three things:
- Creates a new field
__time - Populates that field with a millisecond timestamp
- Uses a simple modulo rule on the session ID field
sidto reduce the data volume by a factor of 10
One notice here: With this setup, sometimes the result of the transform query might be empty. In this case the processor will display an error message about cursor position and route the original FlowFile to the failure relationship. This is not really an error, I am currently ignoring it.
Push Events to the API
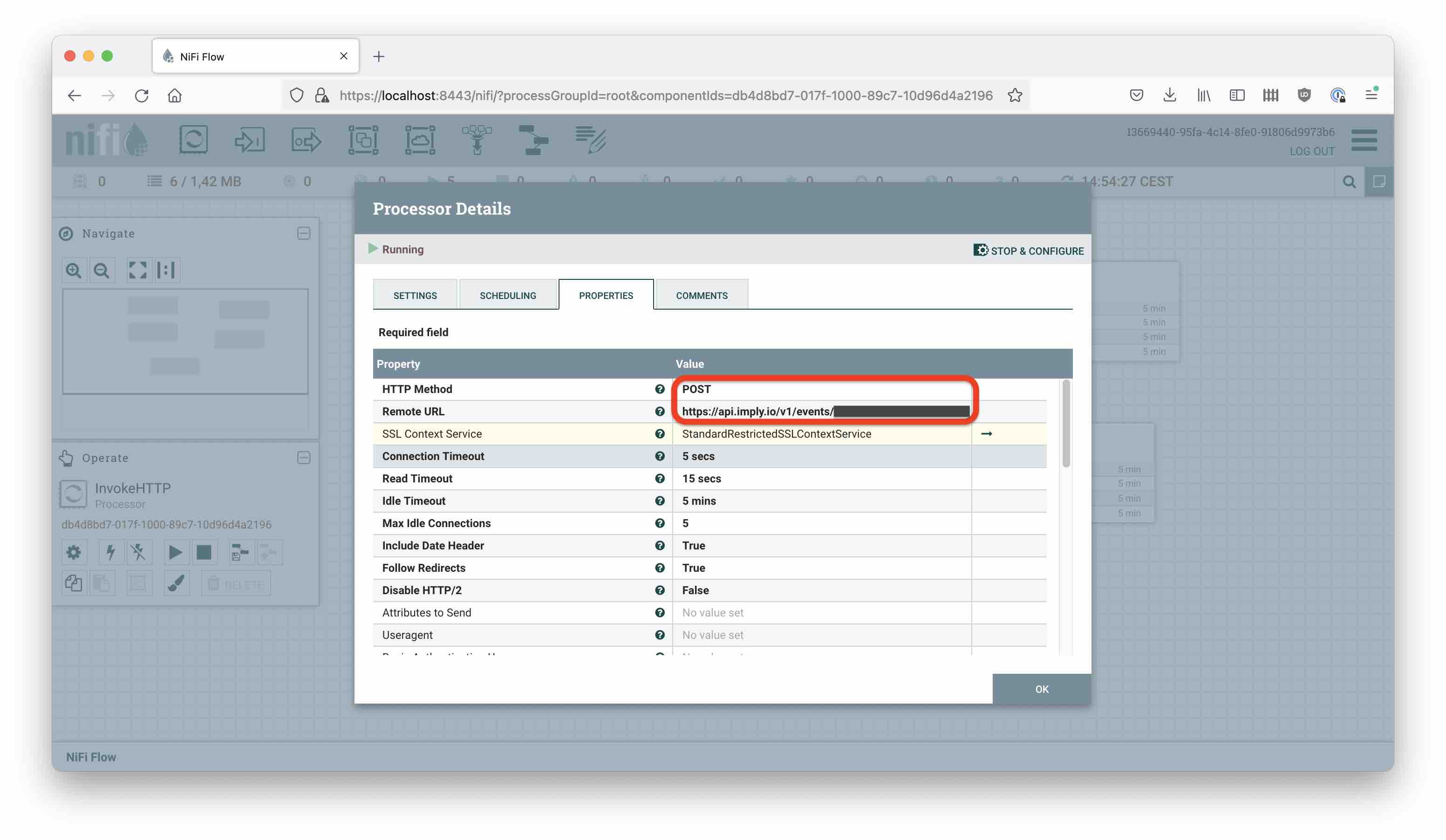
REST calls in NiFi are made using the InvokeHTTP processor. We need:
- the API endpoint URL from above
- Method will be POST
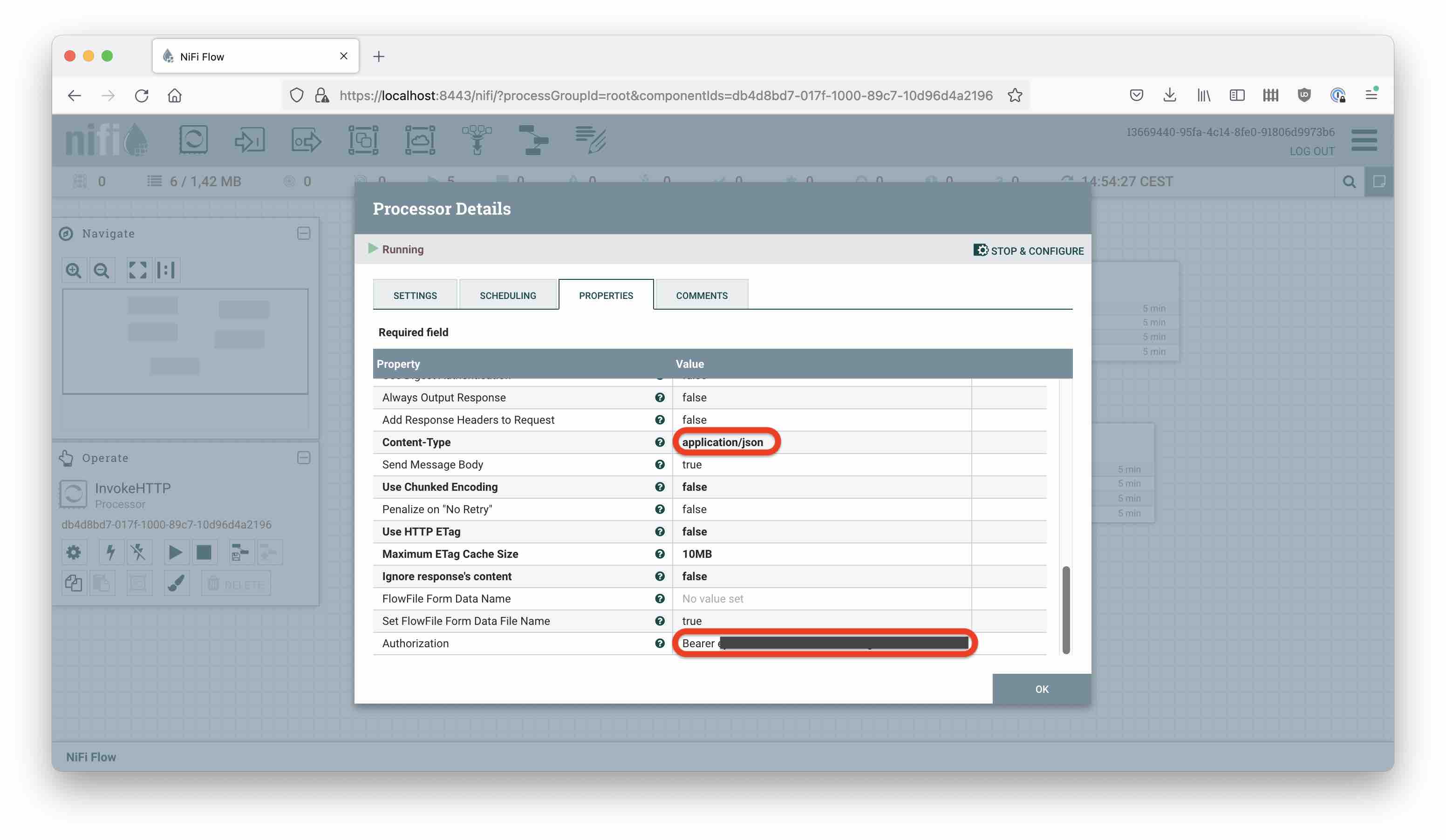
- Set
Content-Typetoapplication/json Authorizationshould beBearerand the literal value of your API token
InvokeHTTP has quite a bunch of relationships, most of which we will auto-terminate. Notable is No Retry, which would catch any batch that is too big. Conversely, the retry relationship catches any transient failures (typically a 503 error). These, we throttle using ControlRate:
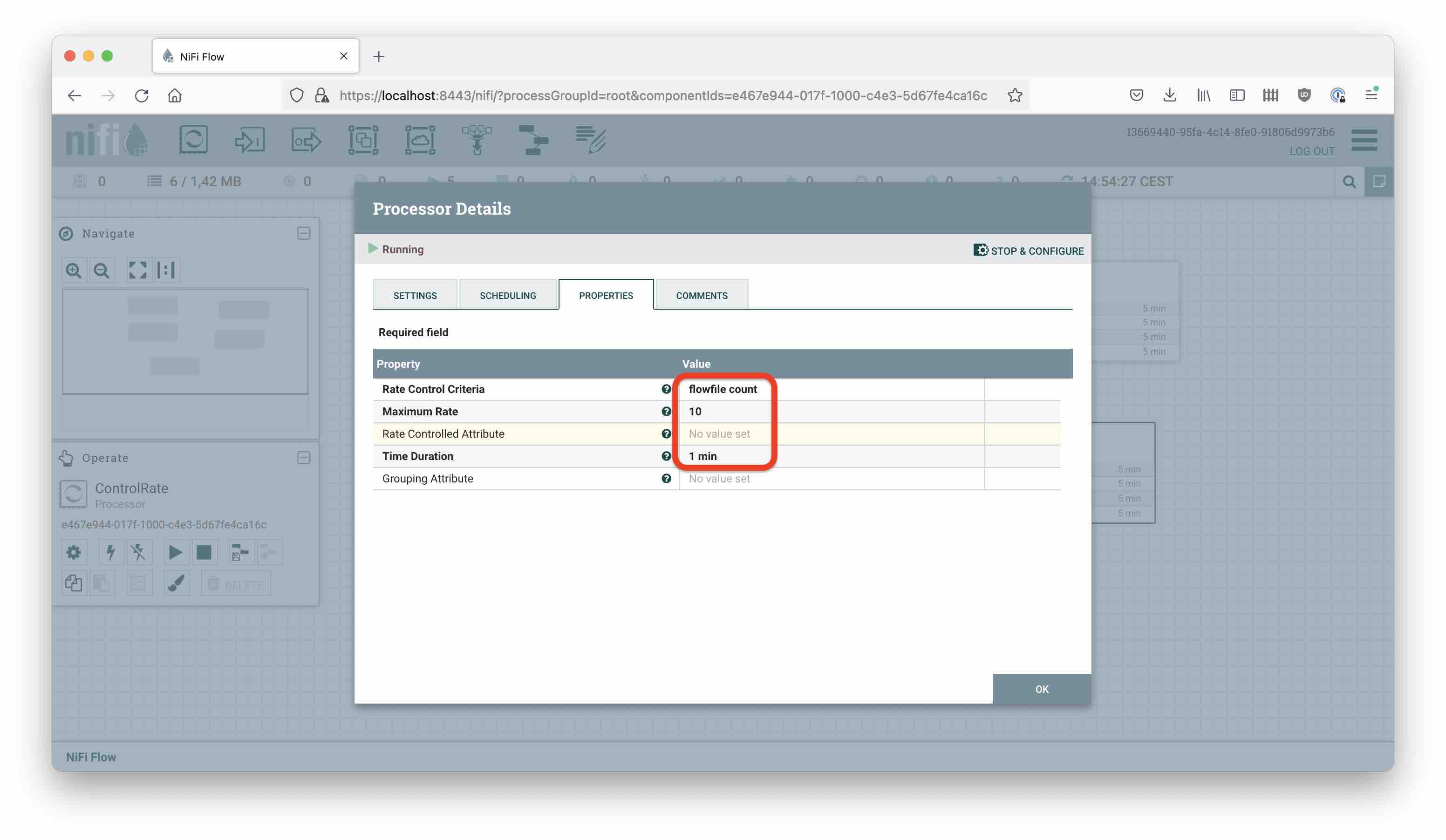
and regurgitate afterwards.
Result
Here’s the final result in Polaris:
Learnings
- Imply Polaris currently supports event streaming through a Push API.
- Apache NiFi is a very flexible tool that can connect a Kafka stream to the Polaris Push API.
- NiFi’s record processors make preprocessing and filtering easy.