Reading Avro Streams from Confluent Cloud into Apache Druid
Today I am going to show how to get AVRO data from a schema aware Confluent Cloud cluster into Apache Druid. Use the Druid 0.22 micro-quickstart setup for this exercise.
Data Governance in Kafka and Druid: Enforcing a contract
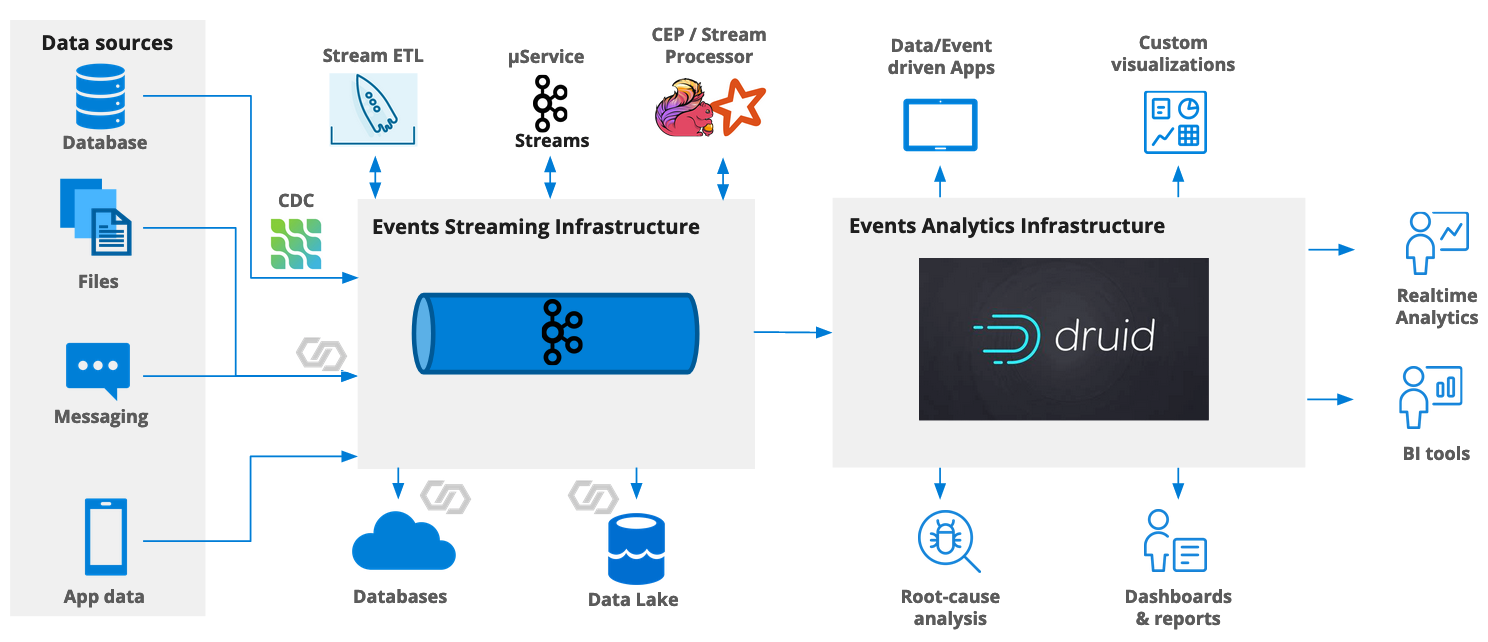
Apache Druid can natively consume data out of a Kafka topic. It is also flexible in picking up new dimensions as they show up in the stream, and can even do so automatically to a certain extent.
Likewise, on the lowest level, Apache Kafka just transmits the message content as a blob of data and does not care what’s in it. However, in a microservices architecture sometimes a stricter control of the data format is desirable. For this, Confluent developed Schema Registry as an extension to Kafka. It is now possible to encode messages in the binary AVRO format. (You can also use JSON or Protobuf with Schema Registry, but that’s a story for another time.)
(Edit 2023-11-08: As of this date, Druid does not yet support JSON with Schema Registry.)
An AVRO object is always accompanied by a schema definition which is itself written in JSON. In the simplest case, the schema definition is sent along with the binary data in each message, which mostly negates the advantages of having a highly compressed binary format.
Therefore, if you use AVRO with Kafka, each message is prepended by a schema ID that references an entry in Schema Registry. Clients can validate schema conformance of each message and make sure that contracts are honored. The exact binary format is documented here.
Druid can read and parse AVRO messages and their schemas. With this integration, Druid automatically picks up the schema definition and allows us to configure the ingestion spec accordingly.
Prerequisite: Configure Druid
In order to parse Avro messages, you first have to enable the Avro extension in the Druid configuration. For the micro-quickstart configuration, edit conf/druid/single-server/micro-quickstart/_common/common.runtime.properties:
# If you specify `druid.extensions.loadList=[]`, Druid won't load any extension from file system.
# If you don't specify `druid.extensions.loadList`, Druid will load all the extensions under root extension directory.
# More info: https://druid.apache.org/docs/latest/operations/including-extensions.html
druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-avro-extensions"]
Then (re-)start Druid.
Setting things up in Confluent Cloud
For this tutorial, I am assuming you have a Confluent Cloud account, as well as an environment and a cluster to work with. We need to set up a few things here:
- a topic that we are going to consume data from
- a service account that will have access only to our tutorial topic
- a Kafka API key and secret associated with that service account
- a schema registry instance where we store the schema definition for our Avro records
- a schema registry API key and secret to access the schema registry
- and finally, a data generator that adds data to the topic, which is part of the managed Kafka Connect service in Confluent Cloud.
Create a topic
For this tutorial, create a topic tut-avro with default settings. (We are only using little data, so there is no point in tuning the configuration.) You can do this in the GUI using Topics > Add topic.
Service account and API credentials
Navigate to Data integration > API keys > Add key. You will be asked whether your key should be allowed global or granular access:
- Global access means that the key is owned by your personal user account and shares all its access rights. It also means that, should your account ever be deleted, the API key will expire as well.
- Granular access means that the key is owned by a service account and can be endowed with specific privileges as needed. This is the proper way to set up machine to machine communication.
If you select that last option, you can either use an existing service account, or create a new one. Create a new service account and name it tut-avro-service-account. Add two ACLs to the service account so that the account can read and write the topic tut-avro that you just created. Finally, download the generated API key and secret for later use. Also, note down the Kafka bootstrap server URL. You can find it if you go to Data integration > Clients > New client > Java.
Schema registry
At the bottom left of your cluster’s GUI menu you will find the item Schema Registry. Open it and make sure Schema Registry is enabled.
Once you enable Schema Registry, you will find the API coordinates in the Schema Registry tab of your environment. (A schema registry is defined on environment level and can be shared by multiple clusters.) Note down the API endpoint URL and create a Schema Registry API key and secret using the Edit button in the API credentials section.
Once again, download the API key and secret you just created.
Data generator
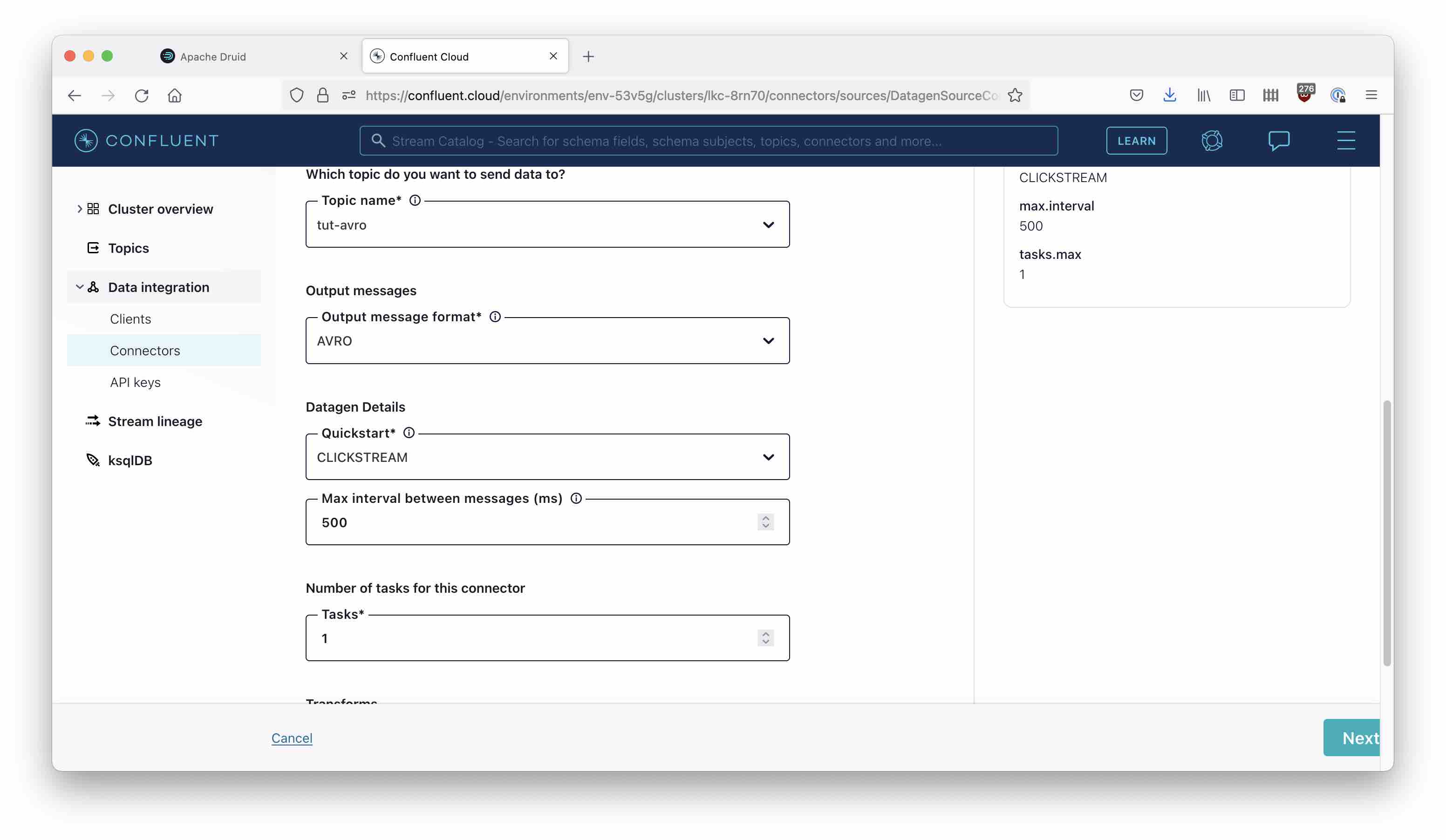
Use the menu navigation Data integration > Connectors > Add connector and select the Datagen Source connector. Enter the Kafka API key and secret you created earlier, and make the topic name tut-avro. Select AVRO as the output format.
Select CLICKSTREAM from the Quickstart menu, enter a message interval of 500 msec, and set the number of tasks to 1 - this will be enough for the experiment:
Start the connector and wait a moment until the topic begins to receive data. If you have everything configured, you can peek into the topic in the Confluent Cloud GUI and verify that data is arriving.
First attempt to ingest these data into Druid
In Druid, start the ingestion from the console.
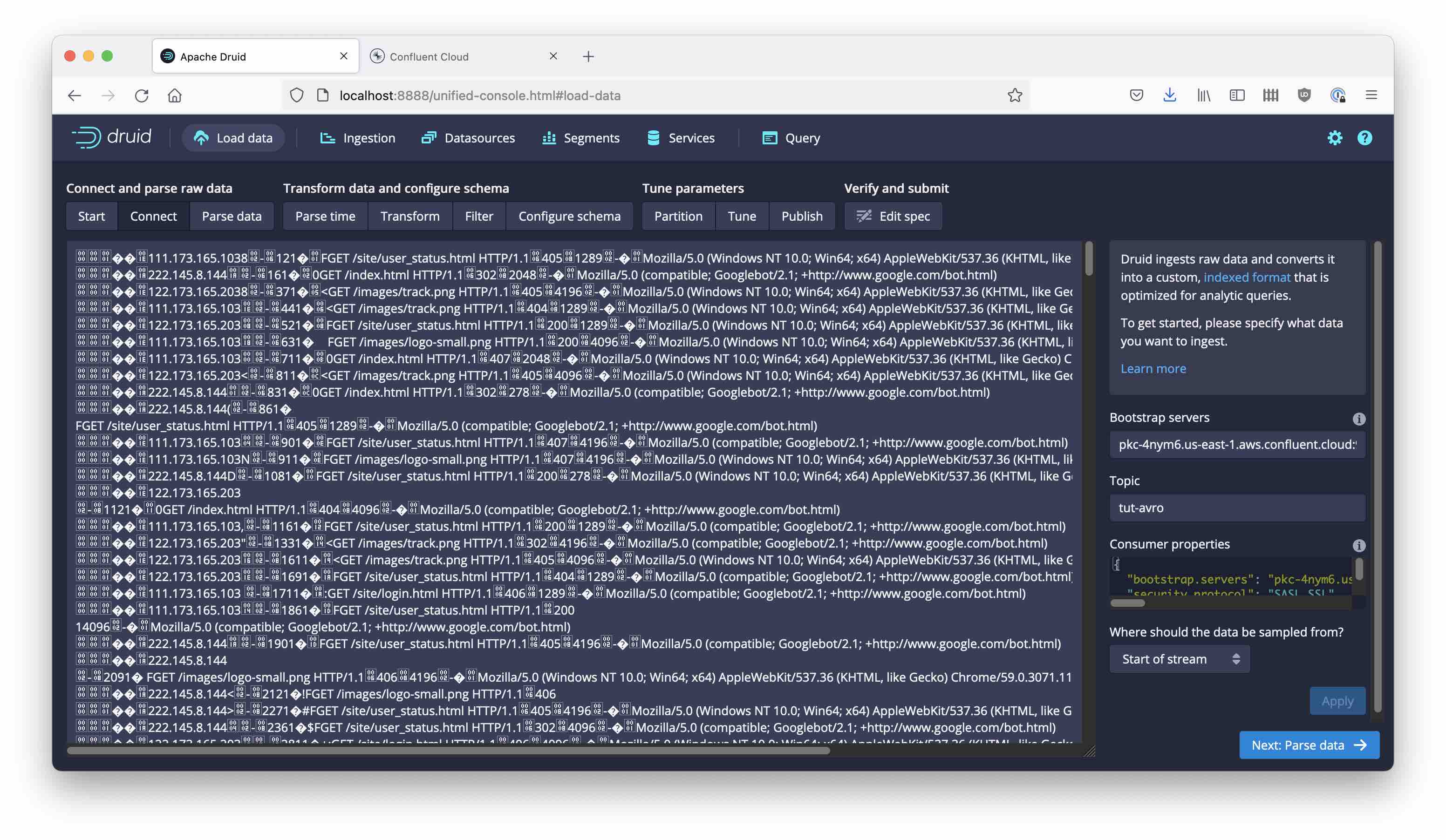
Since Confluent Cloud secures access to Kafka, you need to paste the consumer properties into the little window in the wizard
{
"bootstrap.servers": "<KAFKA BOOTSTRAP SERVER>",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "PLAIN",
"sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"<KAFKA API KEY>\" password=\"<KAFKA SECRET>\";"
}
This will automatically populate the bootstrap server field too. Enter tut-avro as the Kafka topic name and hit Apply. Druid does its best to give you a preview of the data but since it’s a binary format the result looks like gibberish.
Press Next: Parse data, and select the avro_stream input format. This didn’t used to be supported by the Druid wizard, but the ability to parse Avro streams directly from the GUI was recently added.
But what?? … We get the message Error: Failed to sample data: null. This is because Avro needs a schema and we haven’t specified one.
Fixing Schema Registry access
We need to tell Druid where to find the schema associated with our Avro data: Navigate to Edit spec to the right
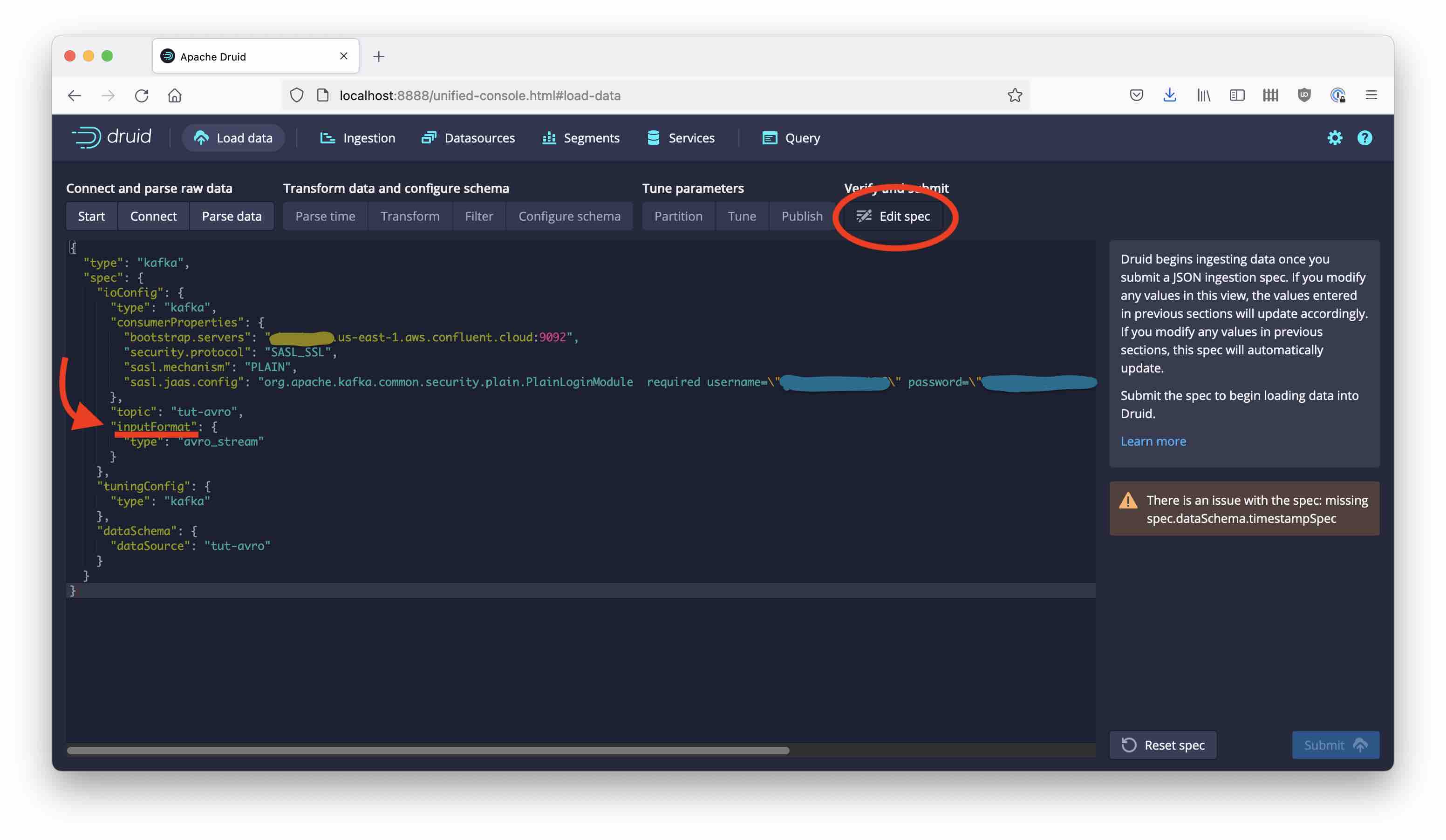
and find the inputFormat section. Replace this by the following snippet:
"inputFormat": {
"type": "avro_stream",
"binaryAsString": false,
"avroBytesDecoder": {
"type": "schema_registry",
"url": "<SCHEMA REGISTRY API ENDPOINT URL>",
"config": {
"basic.auth.credentials.source": "USER_INFO",
"basic.auth.user.info": "<SCHEMA REGISTRY API KEY>:<SCHEMA REGISTRY SECRET>"
}
}
}
replacing the placeholders with the appropriate credentials for your instance of Schema Registry. Then go back to the Parse Data stage.
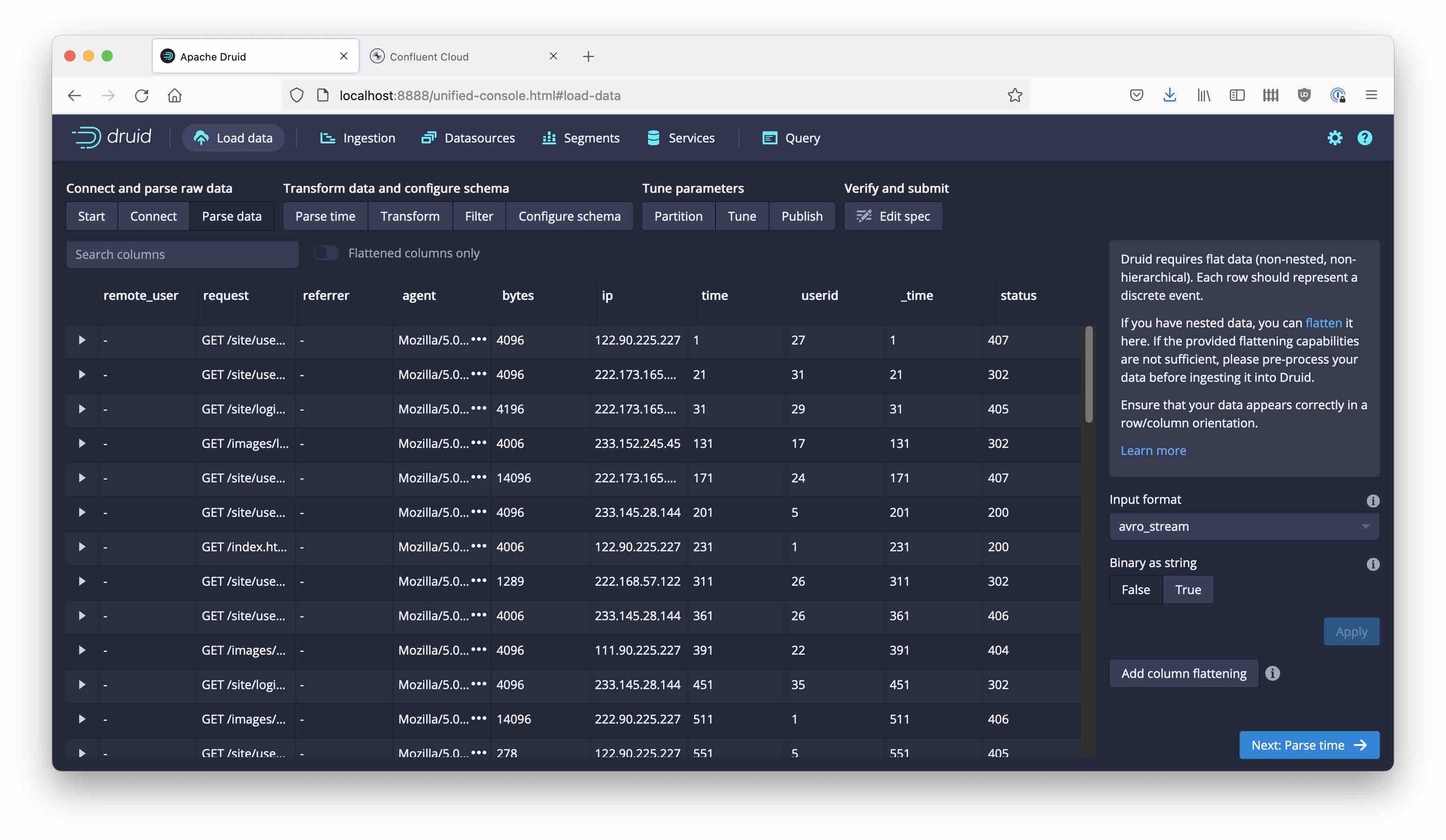
This looks much better!
From here, the rest is easy. Pick the time field as primary timestamp; this comes as seconds since the connector was started, so in a real world scenario you would want to add an offset, but for this tutorial you can leave it as is and interpret it as seconds since Epoch, creating dates in 1970. Submit the spec, and after a short while you will see the first data coming in:
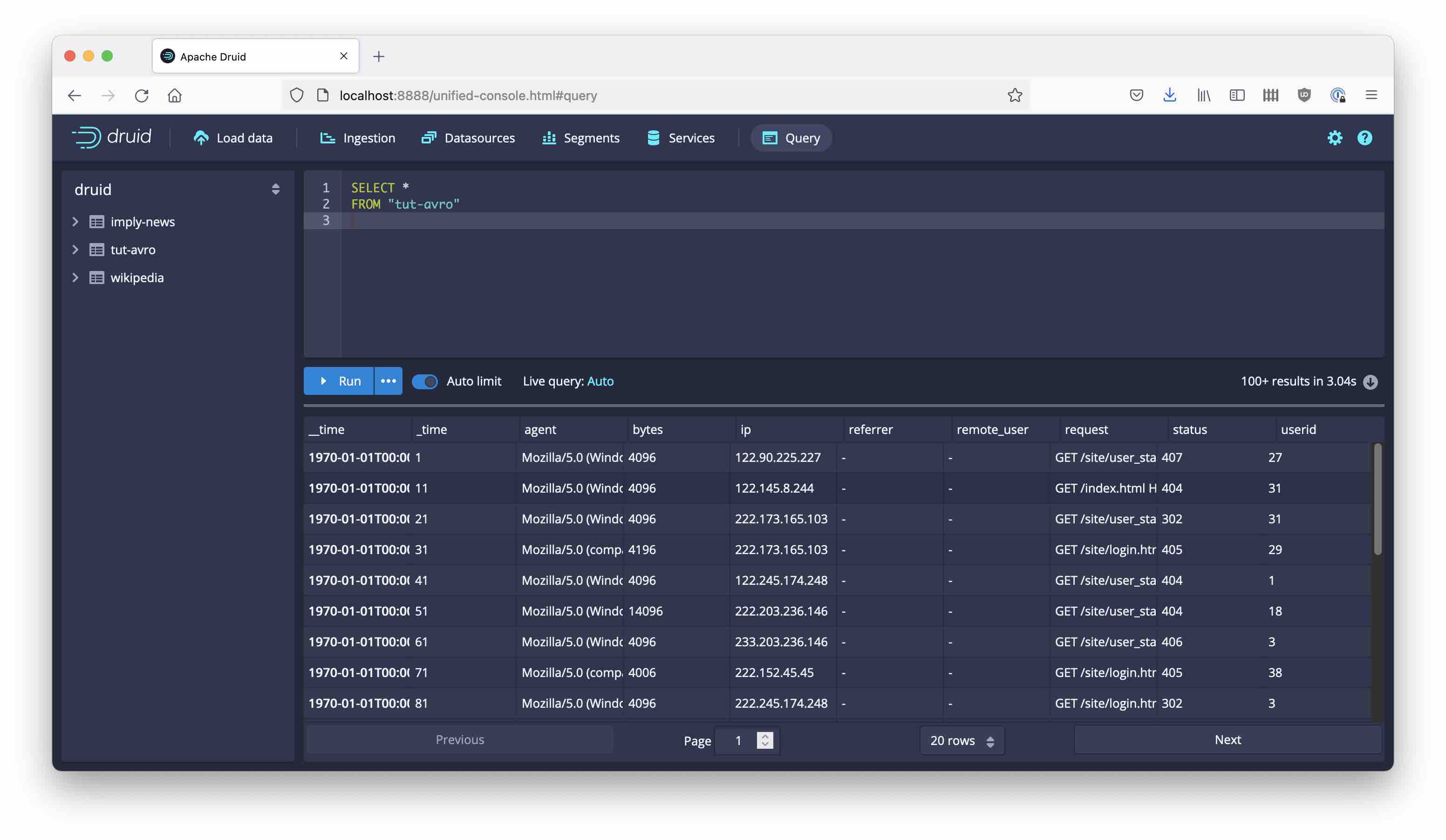
That’s it! We have just integrated Druid with Confluent Schema Registry.
Learnings
- Druid supports ingesting data directly from schema-enabled Kafka in Confluent Cloud.
- You will need two sets of credentials: for Kafka and for Schema Registry.
- A few manual steps are involved in entering the credentials in the proper place.