Partitioning in Druid - Part 2: Single Dimension Partitioning

This is part 2 of the miniseries about data partitioning in Apache Druid. Part 1 can be found here.
Recap
In the previous installment we discussed dynamic partitioning and hash partitioning in Druid. We found out that hash partitioning is great to ensure uniform partition size, but it would not usually help query performance a lot. This is why single dimension (or for short “single dim”) partitioning is available in Druid.
Single Dim Partitioning
Single Dim Partitioning cuts the partition key dimension into intervals and assigns partitions based on these intervals. Let’s find out what this looks like in practice.
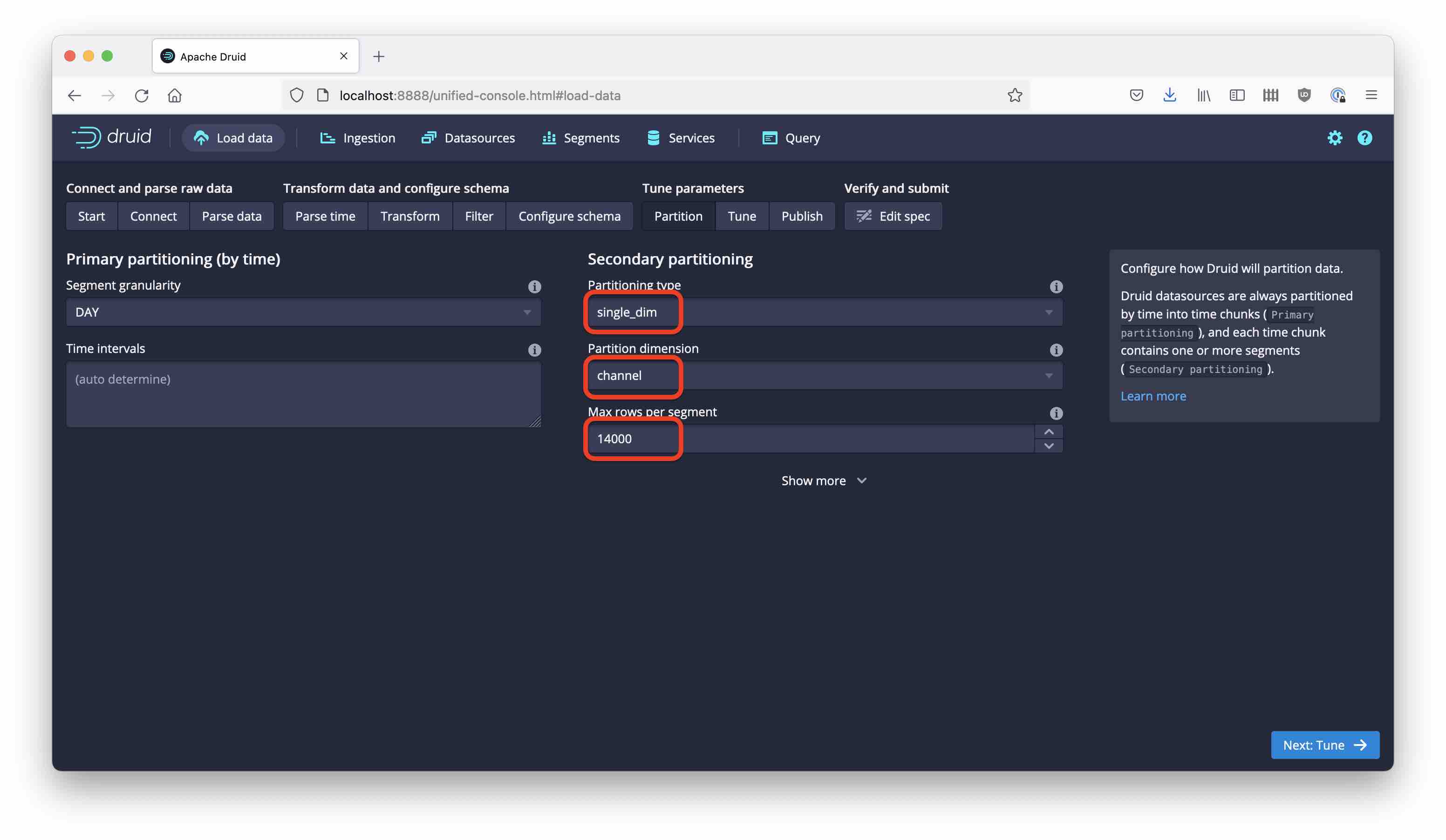
We just chose a different partitioning type. The partition dimension is still channel, and the target size stays the same. Name the datasource wikipedia-single.
Note how the ingestion tasks spawns multiple phases of subtasks. First, there is a task the determines the value distribution of the partition key; then the index is generated, and finally there are three tasks to shuffle the data such that every item ends up in the appropriate partition.
This is what comes out of the ingestion, in terms of key distribution:
Partition 0:
2523 #de.wikipedia
478 #ca.wikipedia
423 #ar.wikipedia
251 #el.wikipedia
222 #cs.wikipedia
Partition 1:
11549 #en.wikipedia
2099 #fr.wikipedia
1383 #it.wikipedia
1256 #es.wikipedia
749 #ja.wikipedia
Partition 2:
9747 #vi.wikipedia
1386 #ru.wikipedia
1126 #zh.wikipedia
983 #uz.wikipedia
263 #uk.wikipedia
(I have used the same script as in part 1 and adjusted the datasource name.)
We can see how the channel values are now neatly sorted into alphabetic buckets. There is actually an even better way to view these data by issuing a segment metadata query. This is a type of query that is used internally by a Druid cluster all the time in order to know which data lives where, but there is no reason why we wouldn’t issue such a query directly.
Here is the (native) query I am using:
{
"queryType": "segmentMetadata",
"dataSource": "wikipedia-single",
"intervals": [
"2013-01-01/2016-01-01"
],
"toInclude": {
"type": "list",
"columns": [
"channel"
]
}
}
I am restricting the query to return only metadata for the channel column. We can view the result in the Druid console:
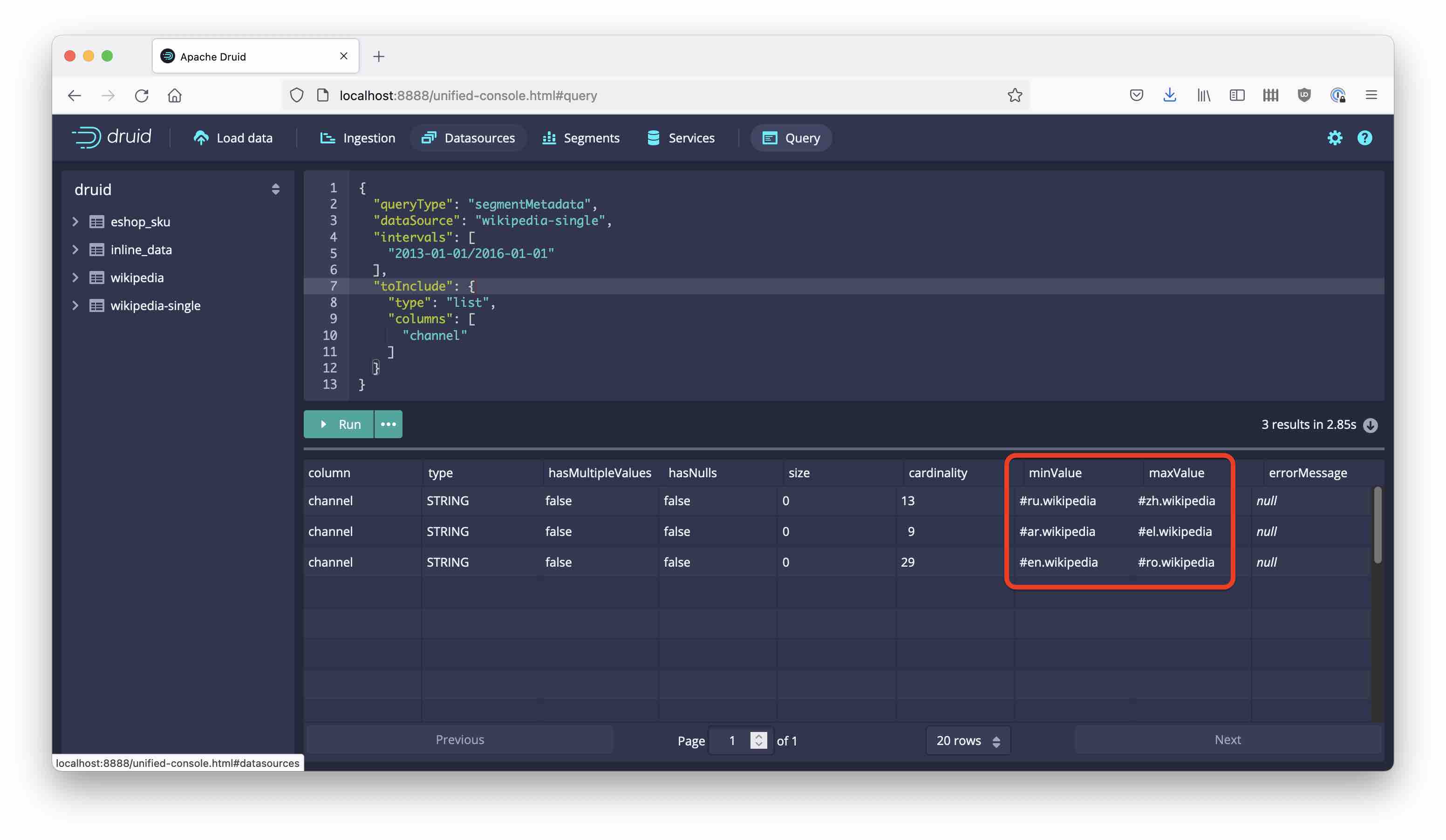
This is quite nice. All rows for a given value of channel end up in the same partition, which has several advantages:
- Filtered queries can read only the segment files that are relevant to them. Imagine a multi-tenant system where each query is usually filtered by a single customer. These queries will benefit a lot.
- Group By queries can do most of the work on the historical nodes and require less shuffling on the brokers.
- TopN queries over the partition key will give greater accuracy, particularly if there are a lot of values with similar frequency.
However, there’s a catch. Let’s look at the segments we created:
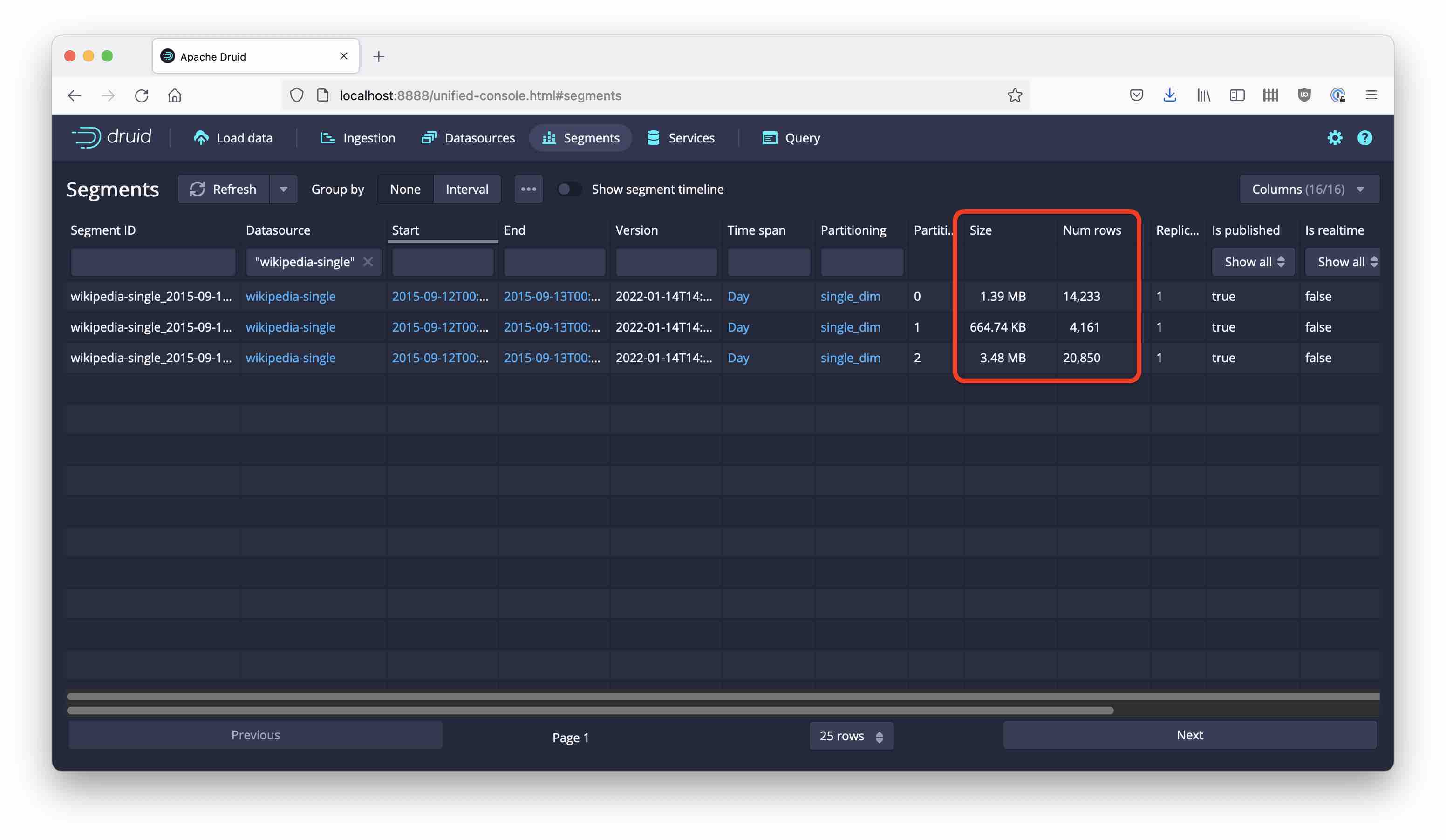
Bummer! These segments are very different in size! Why is that?
Recall the value histogram that we retrieved in the beginning. The distribution is very skewed: Two values (#en.wikipedia, #vi.wikipedia) account for half of all the rows! If all rows for one value go into the same partition, there is no way we can get a balanced size distribution. That is why the remaining partition (number 1 in this case) ends up with only 4,000 rows and 660K in size, while the biggest partition is five times that size. If we had real data rather than this small sample, this would have a big effect on performance.
This is not good news for query tuning. You want to get uniform partition sizes, like what we got with hash partitioning. In the next installment of the series, we will look at a way to achieve both uniform partition size and a data layout that optimizes query performance.
“Remedy Tea Test tubes” by storyvillegirl is licensed under CC BY-SA 2.0, cropped and edited by me