Semi-Structured Data in Apache Druid: Loading HN comments
Today I came across this tweet by a Snowflake engineer:
I just published "Loading all Hacker News comments into Snowflake (in less than 1 minute)"
— Felipe Hoffa (@felipehoffa) December 10, 2021
Includes examples on how @SnowflakeDB makes it easy to query semi-structured data, and its great support for recursive queries.https://t.co/LtoQXT2txR
Thx @newsycombinator!
So, he is exporting semi structured data and sending them to a data warehouse. Apache Druid is perfectly suited for semi-structured data.
Druid can easily adapt to new or changing fields in the data, and it comes with built-in full indexing of all dimensions.
Let’s give it a try!
Preparing the data
You can follow Felipe’s instructions on how to export the data from Google Big Query - I exported everything as gzipped Parquet files.
Ingest these data into your Druid instance. Any Druid version will do, but make sure you have the Parquet and Google extensions enabled. Also, follow the instructions on setting up GCS access in the docs if you don’t want to make your data publicly accessible.
Loading the data
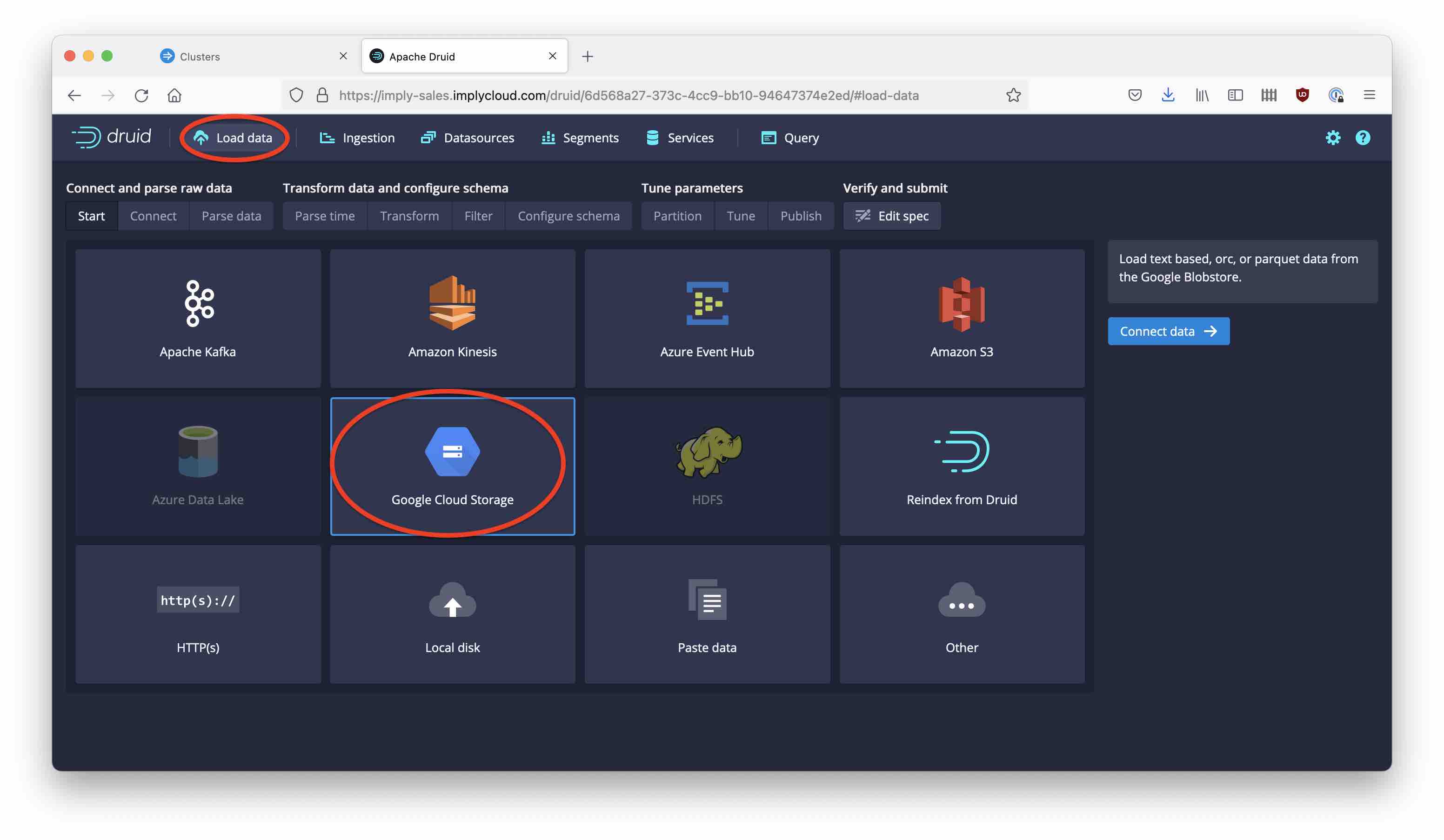
Go to the Load data wizard and select Google Cloud Storage as the source:
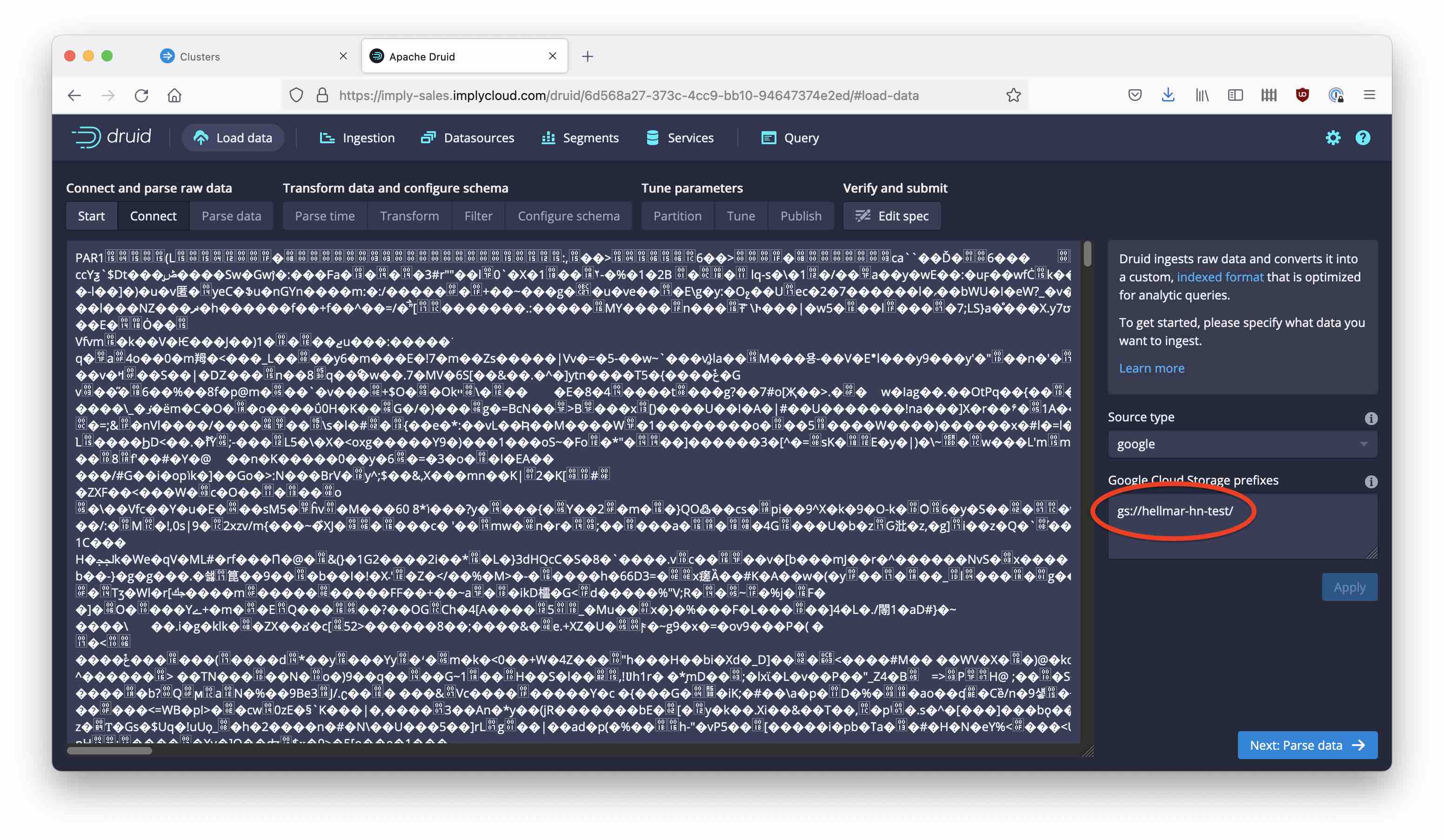
Enter the Google Cloud location where your data resides, in the Google Cloud prefixes field. You will see a (garbled) preview:
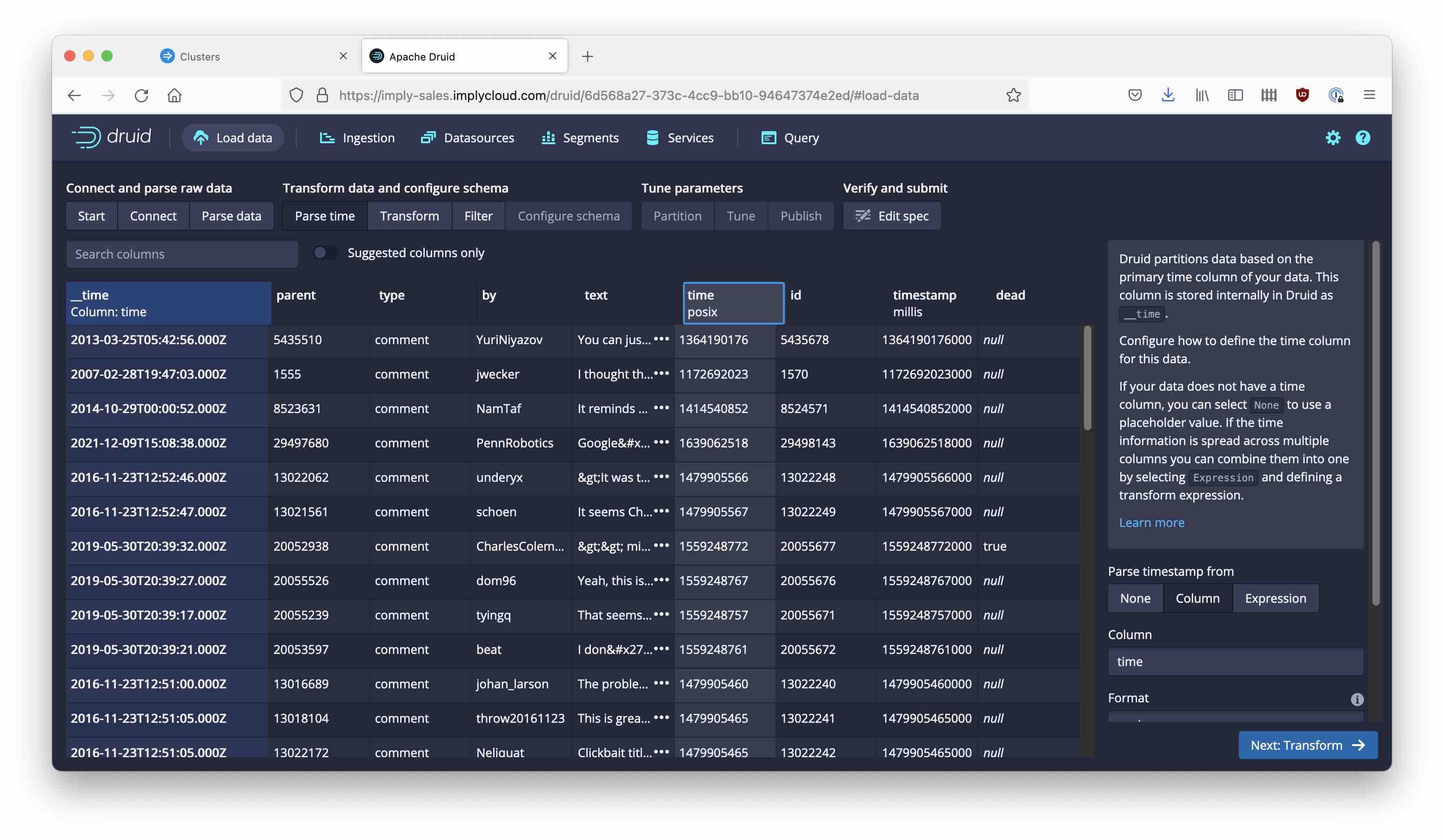
But once you configure the Parquet parser, it all looks fine:
Flexible schemas!
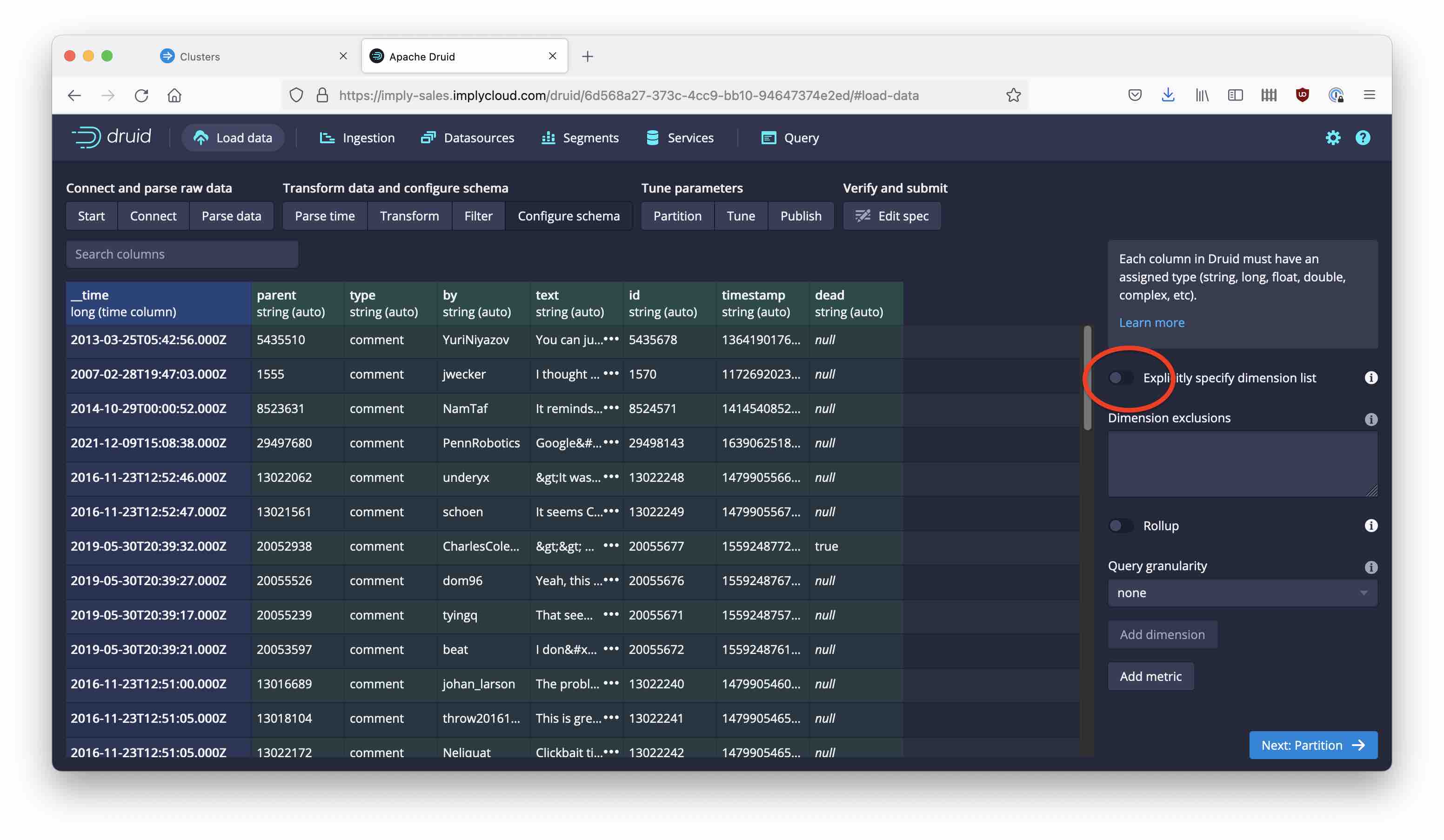
Because the data is semi-structured, we want to be able to pick up any new or changed fields as they occur. This is called schemaless ingestion in Druid and it is the most flexible way to handle semi-structured data. You can flexibly ingest any new fields, and they will be automatically indexed too!
In order to achieve this, in the Configure schema screen, switch the Explicitly specify dimension list toggle to the off position:
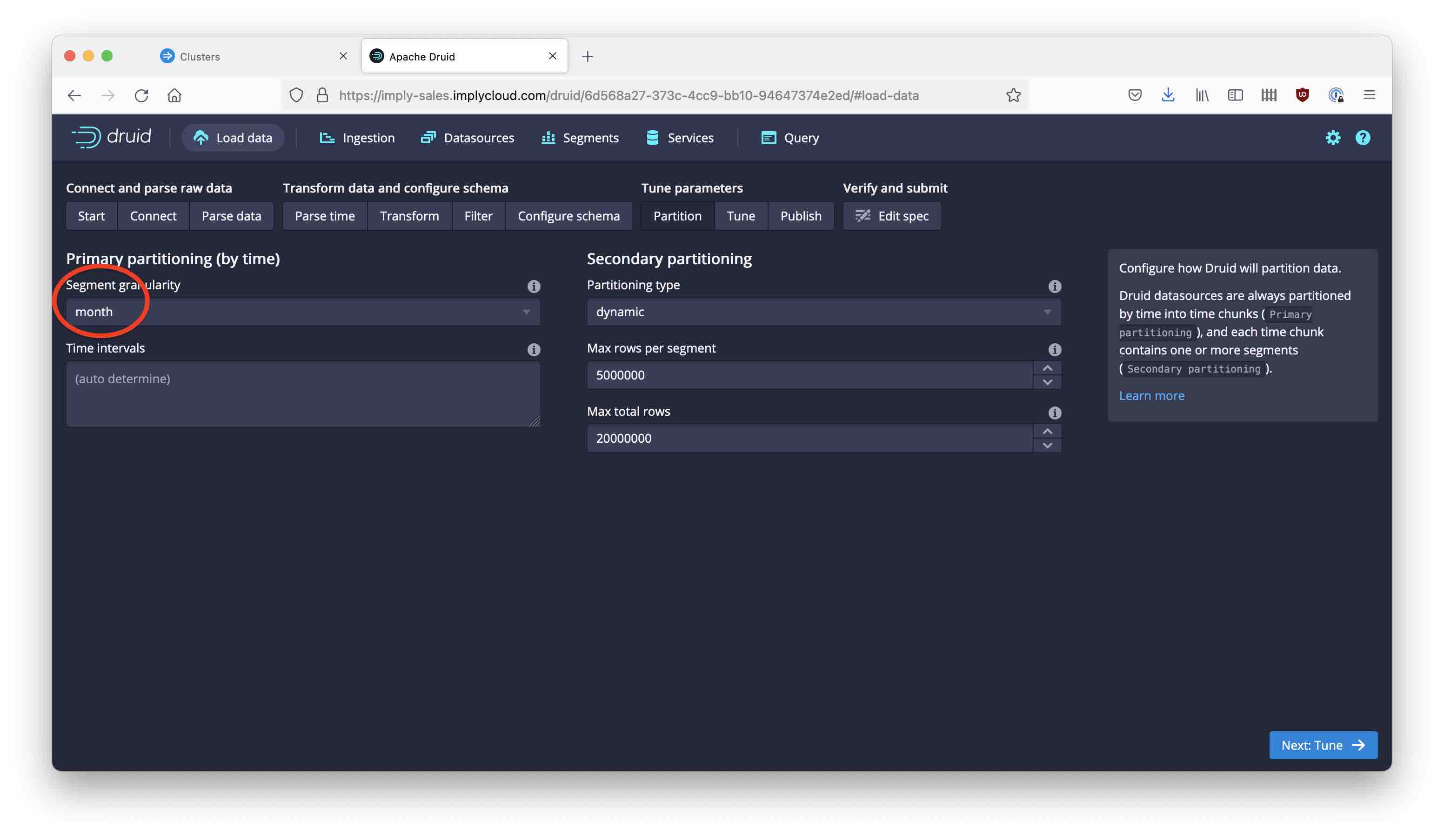
Configure monthly segments and leave dynamic partitioning in place. You could improve things even more by changing the partitioning strategy, but that’s another story for another blogpost.
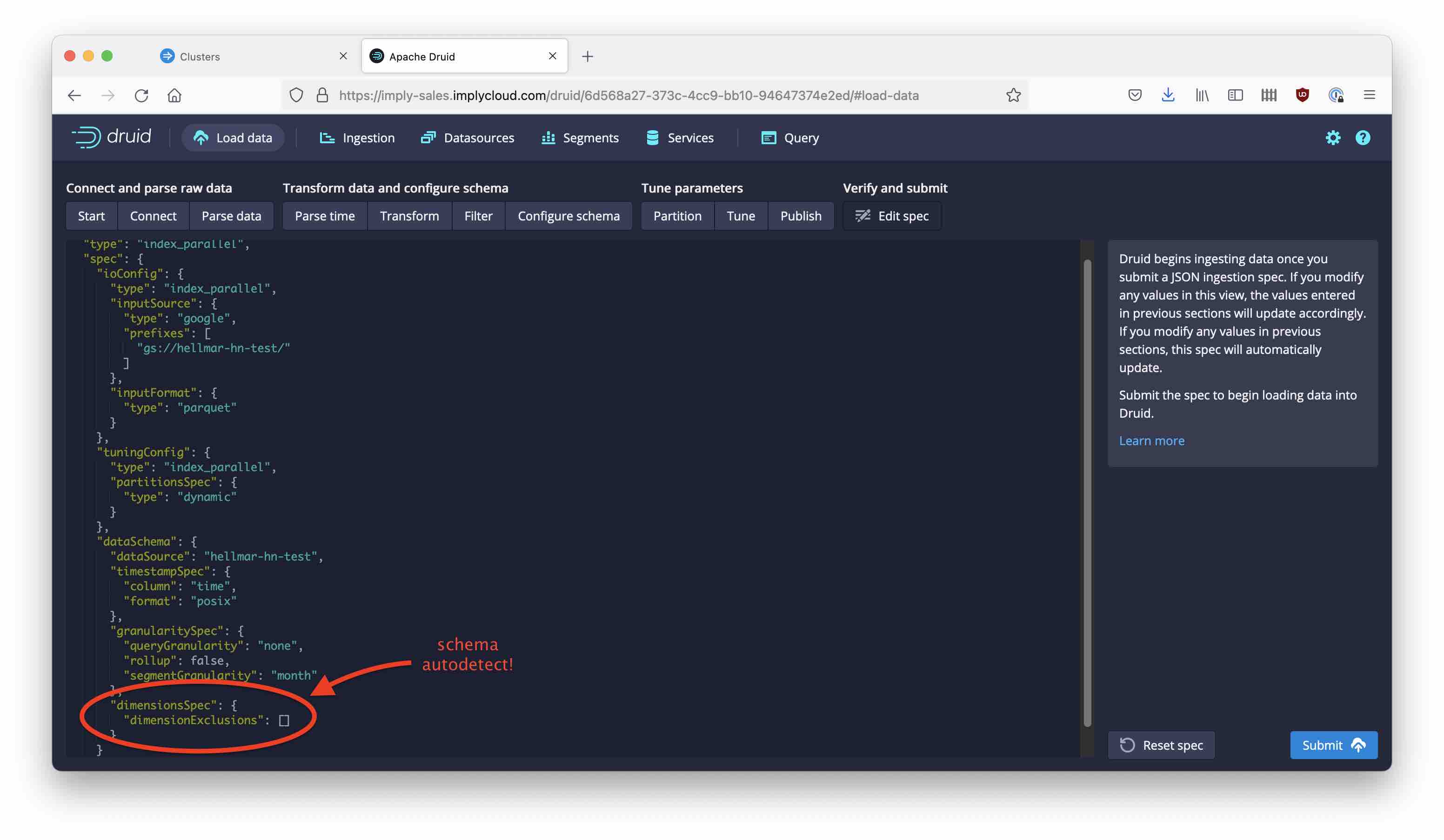
Reviewing the ingestion spec, this is what a schemaless spec looks like:
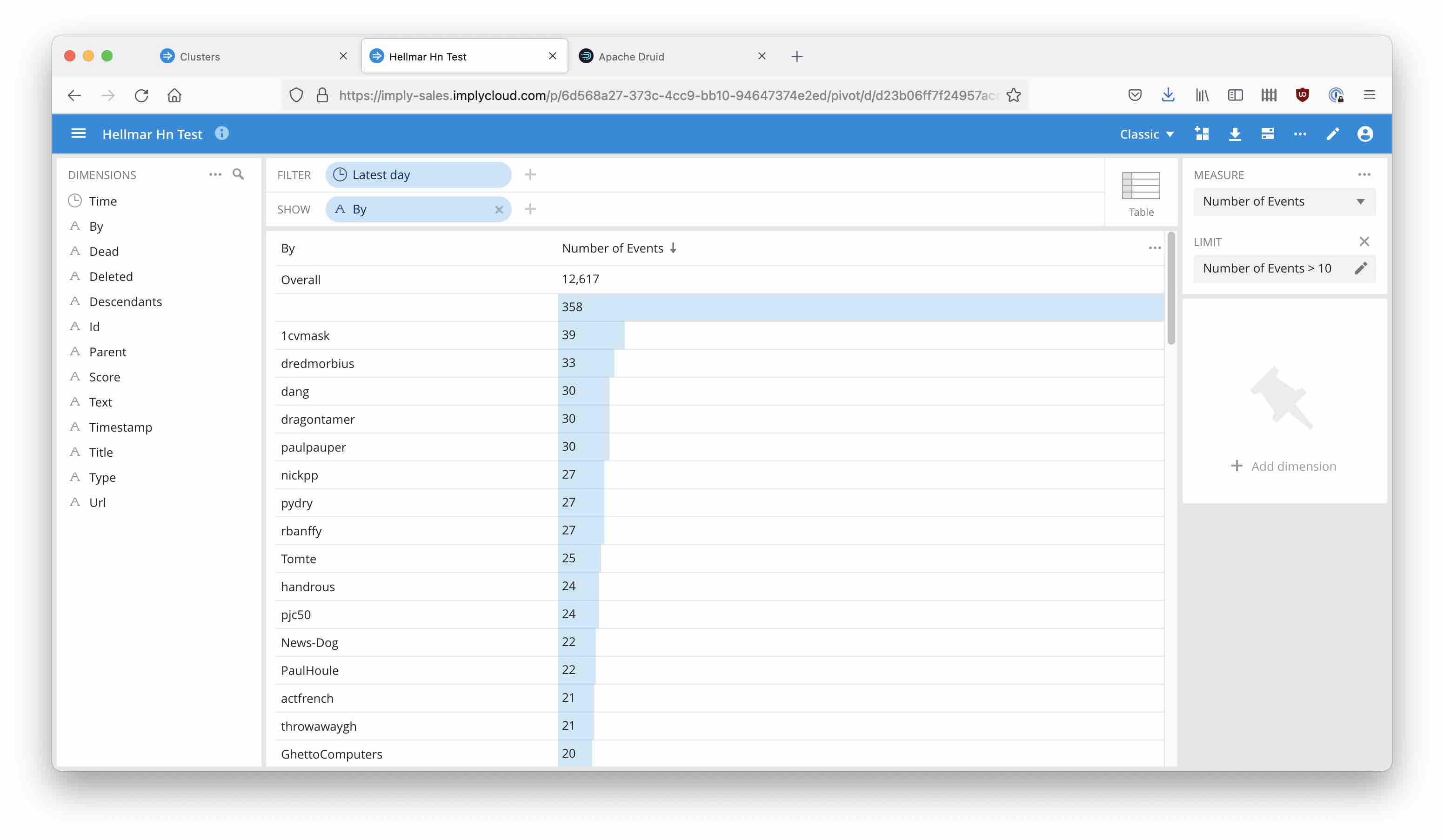
You can query the data directly from the Druid console, or use a tool like Pivot to explore the data:
Learnings
- Apache Druid is built to handle semi-structured data in a very natural way.
- With automatic schema evolution, new fields are picked up seamlessly.
- As a bonus, all the fields are indexed.
- This allows for super fast data exploration, and the ability to power web apps!