Experiments with Schema Evolution in Apache Druid
Apache Druid is known for its ability to handle schema changes during data ingestion and query in an extraordinarily flexible way. Normally, you don’t even need to worry because everything is handled automatically for you. However, there are a few edge cases that data engineers and data analysts should be aware of. Let’s have a look.
We are going to create a very simplistic datasource (that’s what we call the tables inside Druid). It is going to have just two rows of data and two columns: a timestamp and an integer.
Getting Started
Create an inline datasource in the Druid Wizard and paste the following bit of data:
ts,value
2021-01-01,1
2021-01-02,2
Go through all the steps of schema creation. Make sure you use the CSV parser (see below for an example); otherwise, accept the defaults. Choose monthly segments, because we want to add more data in the next steps. Again, continue through all the steps, accepting the defaults.
Pick a meaningful name for your datasource, for instance schema_evolution. By default, Druid suggests inline_data as the data source name for pasted data, which makes it too easy to mix up data from different experiments, creating a lot more schema evolution than you probably want to handle.
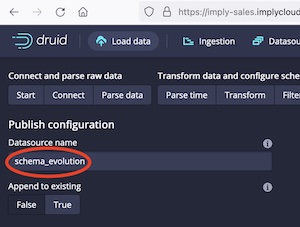
Submit the ingestion task and wait until it is finished.
You just created a datasource that has 2 rows of data and is arguably not particularly interesting. Let’s run a simple query:
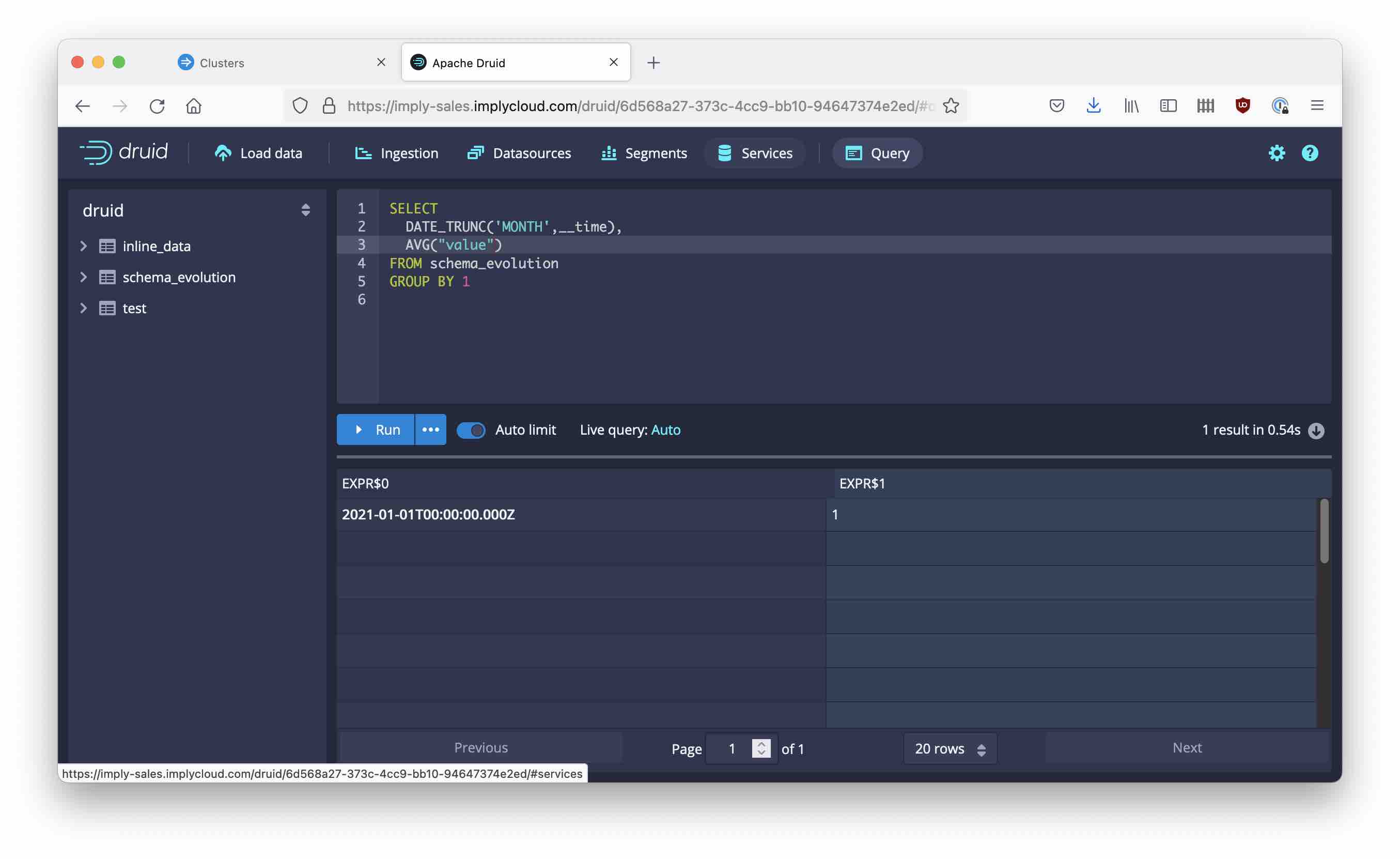
Note how the AVG() function yields an integer value. This is actually expected behavior because the value column itself is integer. We can fix the query by writing
SELECT
DATE_TRUNC('MONTH',__time),
AVG(CAST("value" AS DOUBLE))
FROM schema_evolution
GROUP BY 1
Schema Evolution!
Now, let’s try something different. The column names will be the same but the value field now contains a string rather than a number. This is conveniently handled by using Continue fom previous spec in the data loader, and pasting the new values:
ts,value
2021-02-01,aaa1
2021-02-02,aaa2
If you move forward to the Configure schema tab, you may notice that Druid still thinks of value as a long, and shows null values. Uncheck the Explicitly specify dimension list switch to enable automatic type detection:
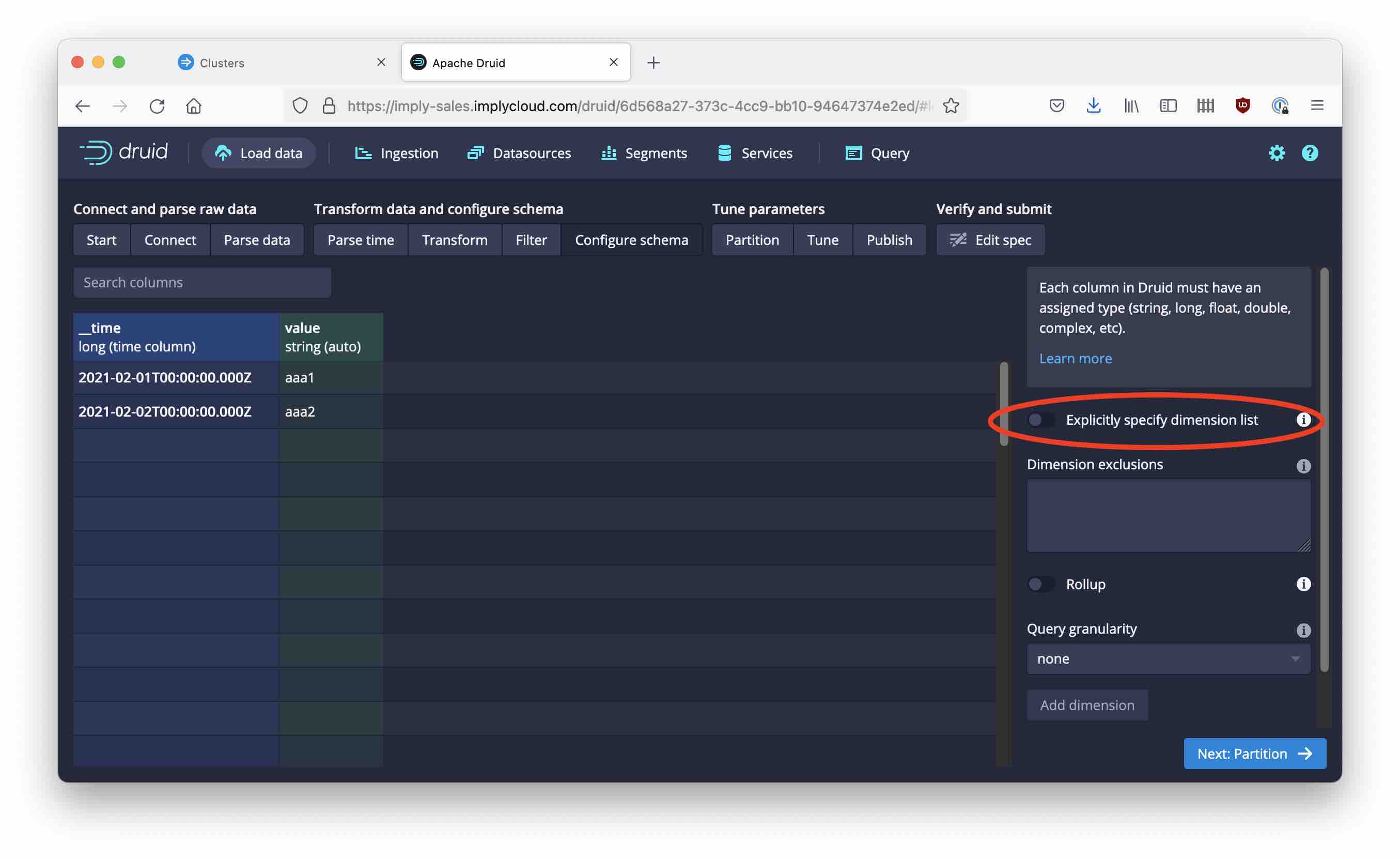
After the ingestion task finishes, move back to the Query tab. Look at the table metadata: The value column has a string type now! Let’s run the same query as before.
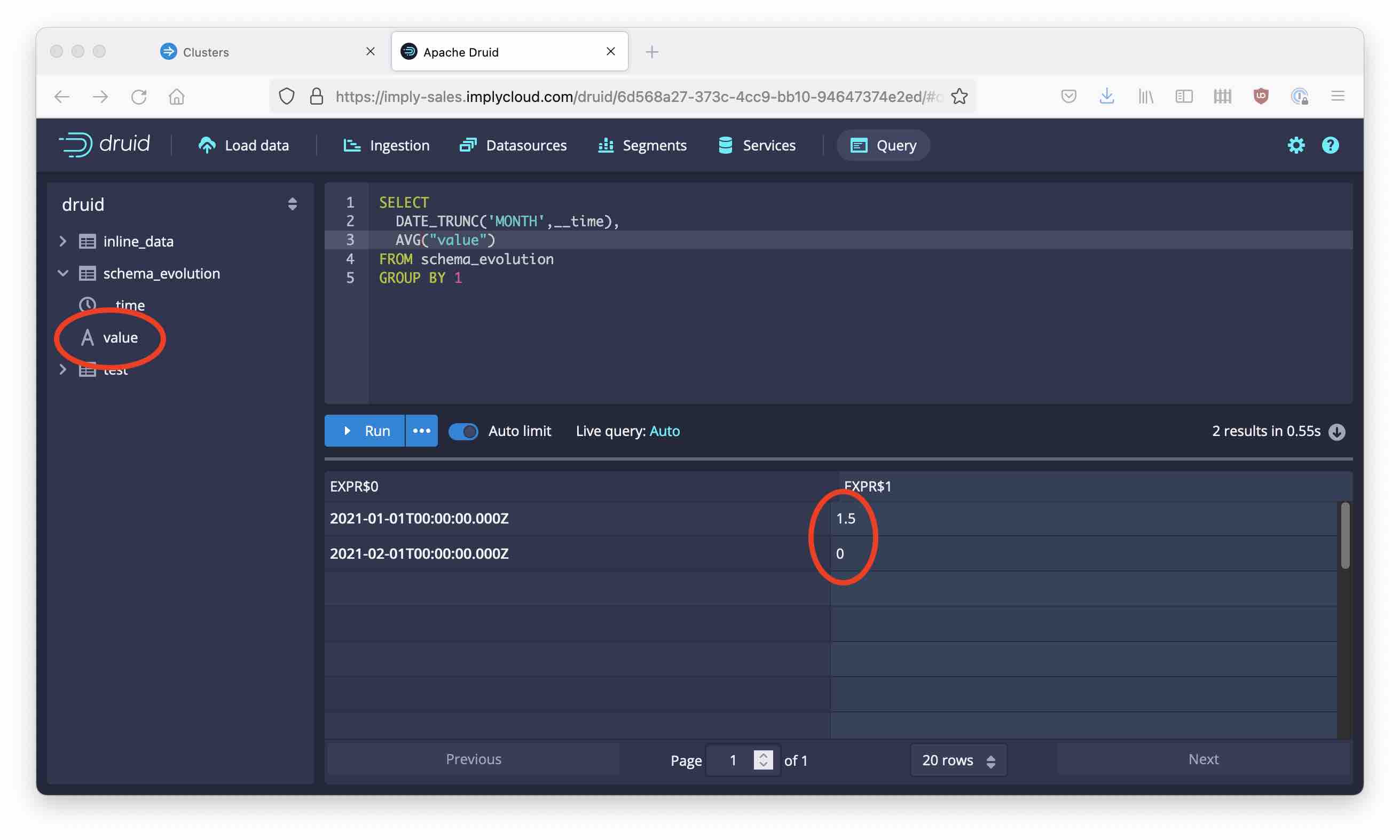
We can still get the numeric aggregate functions out of our datasource, because Druid SQL inserts an implicit type conversion for us. However, if you try this instead:
SELECT
DATE_TRUNC('MONTH',__time),
MAX("value")
FROM schema_evolution
GROUP BY 1
you get an exception because Druid cannot map the argument to a unique type. You have to write MAX(CAST("value" AS double)) in order to make the query work.
Finally, let’s ingest another set of data with string values. This one, however, has a multi-value dimension.
ts,value
2021-03-01,a|b
2021-03-02,c|d
Here’s how to configure the parser.
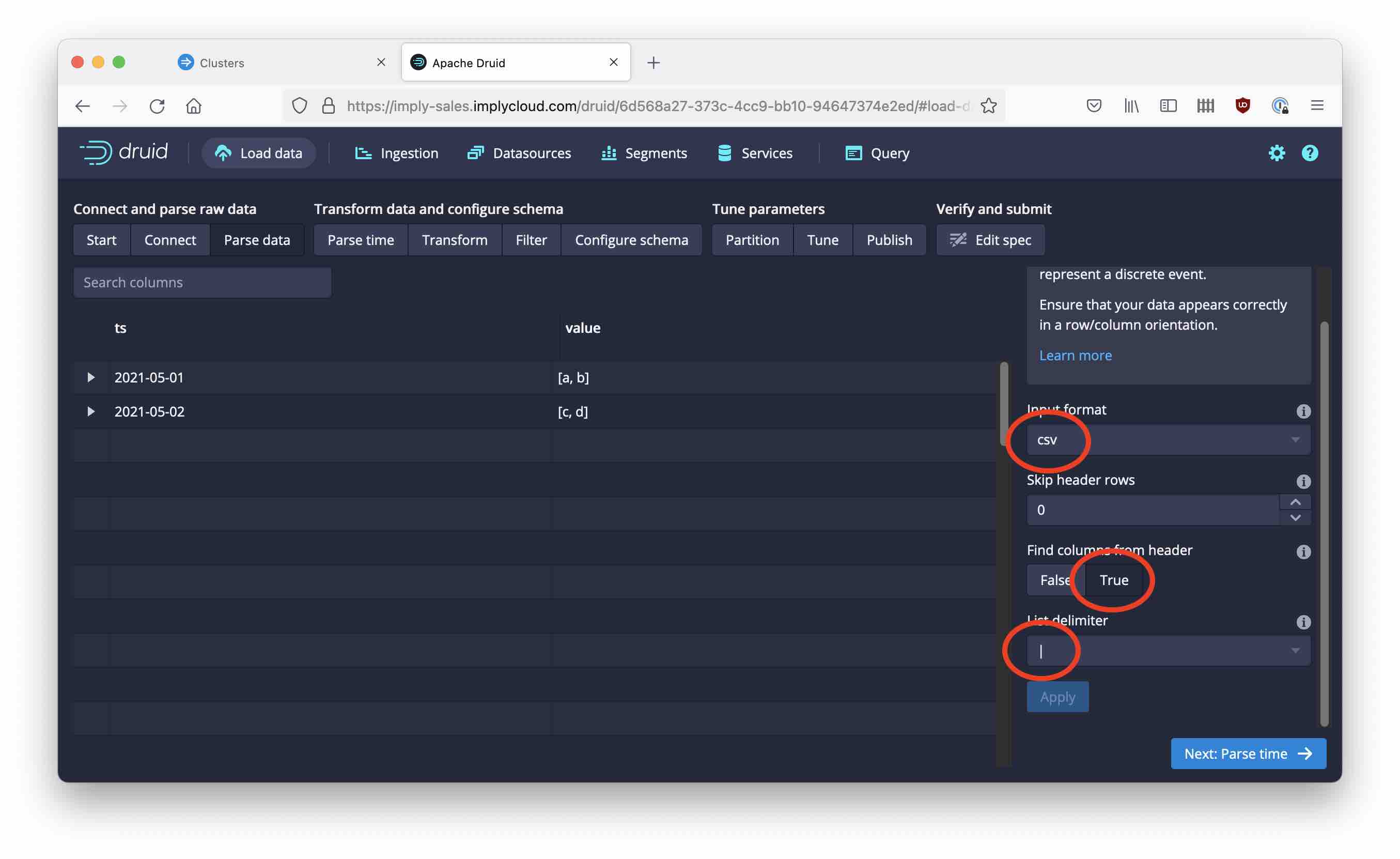
Finish the ingestion and try the query again:
SELECT
DATE_TRUNC('MONTH',__time),
AVG("value")
FROM schema_evolution
GROUP BY 1
Oh no! We get a Java exception. Let’s fix the query by picking the first element of each multivalue array only:
SELECT
DATE_TRUNC('MONTH',__time),
AVG(MV_OFFSET("value", 0))
FROM schema_evolution
GROUP BY 1
And this way, the query works!
You are encouraged to do more experiments with schema evolution. For instance, if you change a column from string to number type, the string values will all appear as null. But they are still there! CAST("value" AS VARCHAR) will bring them back.
Learnings
Druid is amazingly flexible with regards to schema evolution. Often times, this is handled quietly without problems. In case of type conflicts:
- When segments have columns of the same name but a different type, the data dictionary will record the last column type that was ingested.
- If you have to run a SQL query that spans across such segments, in many cases you can get away with implicit type conversions.
- You can always get at the original data that is stored in a segment, using a CAST function.
- If you have difficulty extracting values from a multivalue dimension, array functions are your friend.