Multi-Value Dimensions in Apache Druid (Part 3)
In which we continue the quest about multi-value handling and try to answer the question: Why are we even doing this?
This is part 3 of the miniseries about multi-value dimensions in Apache Druid. More posts can be found here:
After part 2 of the multi-value series, one reader asked what the difference between the types of handling is and why he would even bother about it. Let’s look at some scenarios.
Let’s assume I am running an Italian restaurant. Each time one of my patrons visits, I am noting down which items they consume as part of a menu, in order.
I might end up getting something like this:
{ "date": "2021-09-25", "customer": "Fangjin", "orders": [ "pizza", "tiramisu", "espresso", "espresso" ] }
{ "date": "2021-09-25", "customer": "Gian", "orders": [ "pizza", "espresso", "tiramisu" ] }
{ "date": "2021-09-25", "customer": "Vadim", "orders": [ "pizza", "tiramisu" ] }
{ "date": "2021-09-25", "customer": "Rachel", "orders": [ "pizza", "tiramisu", "espresso" ] }
{ "date": "2021-09-25", "customer": "Xiaolan", "orders": [ "pizza", "espresso" ] }
{ "date": "2021-09-25", "customer": "Jessy", "orders": [ "pizza", "espresso", "espresso" ] }
Probably none of these customers will ever do these exact orders in real life, but let’s keep this for educational purposes only.
Also note that I am intentionally leaving the question open whether the pizza has pineapples.
Ingest this data sample into Druid by copypasting it into the inline ingestion wizard. The previous articles in the series explain how to do that. This time, we have JSON data, which means no additional configuration is needed.
Create virtual copies of the orders dimension using the transform step:
![]()
Don’t worry that the order of the fields looks all messed up, we’ll fix that in a moment. Continue the ingestion wizard, entering day as the segment granularity value, set the datasource name to ristorante, and proceed all the way to the screen where you can edit the JSON spec.
Find the dimensionSpec part and replace the dimension list by this snippet:
"dimensions": [
"customer",
{
"type": "string",
"name": "orders",
"multiValueHandling": "ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "orders_sorted",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "orders_set",
"multiValueHandling": "SORTED_SET",
"createBitmapIndex": true
}
]
The result looks similar to this:
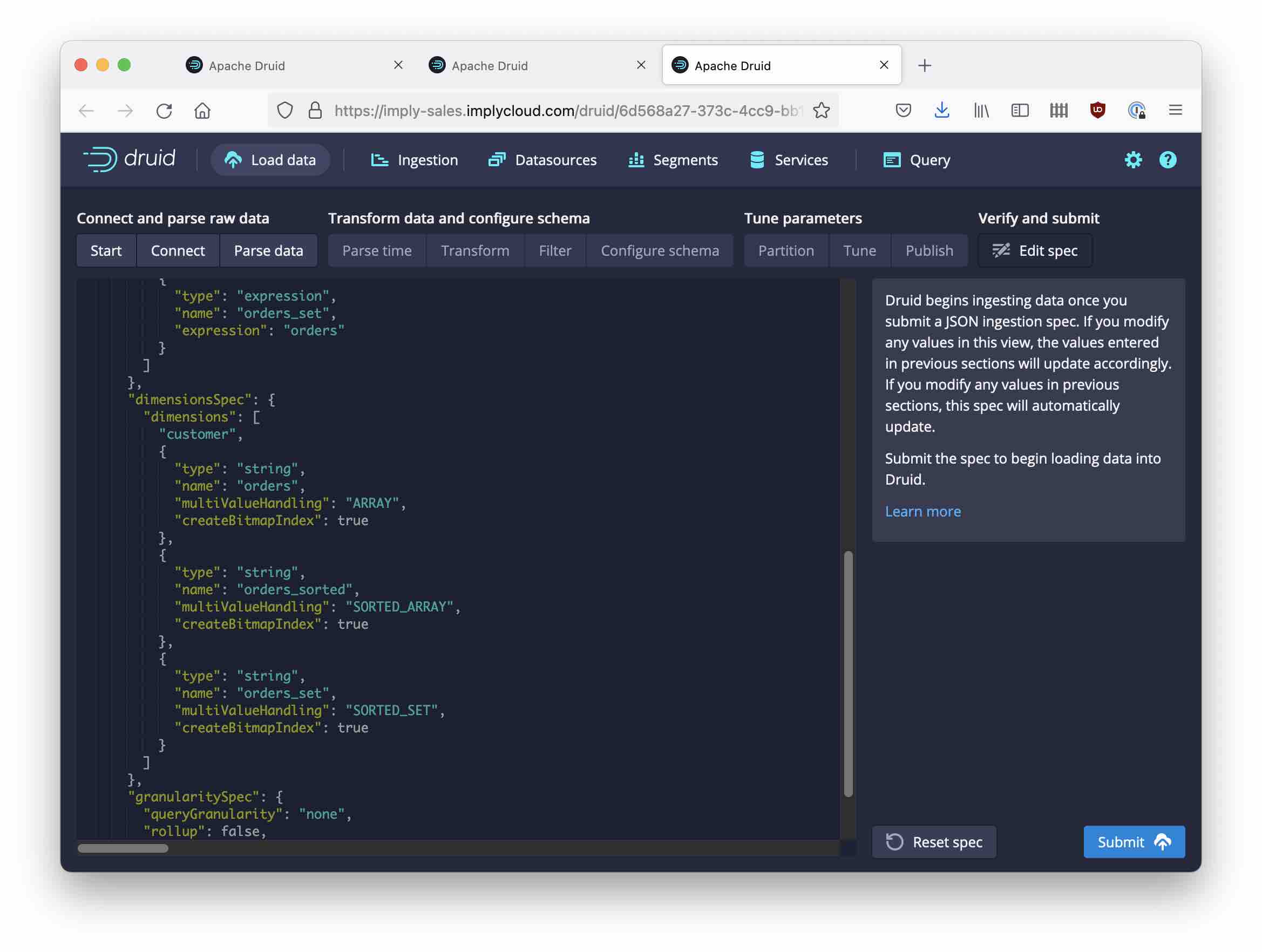
Note how I am starting with the ARRAY representation because it preserves the original order and frequency of the data.
First Queries
Let’s run a few queries. I am using Druid SQL so that analysts that come from another database system can easily adapt.
How many of each dish did I sell?
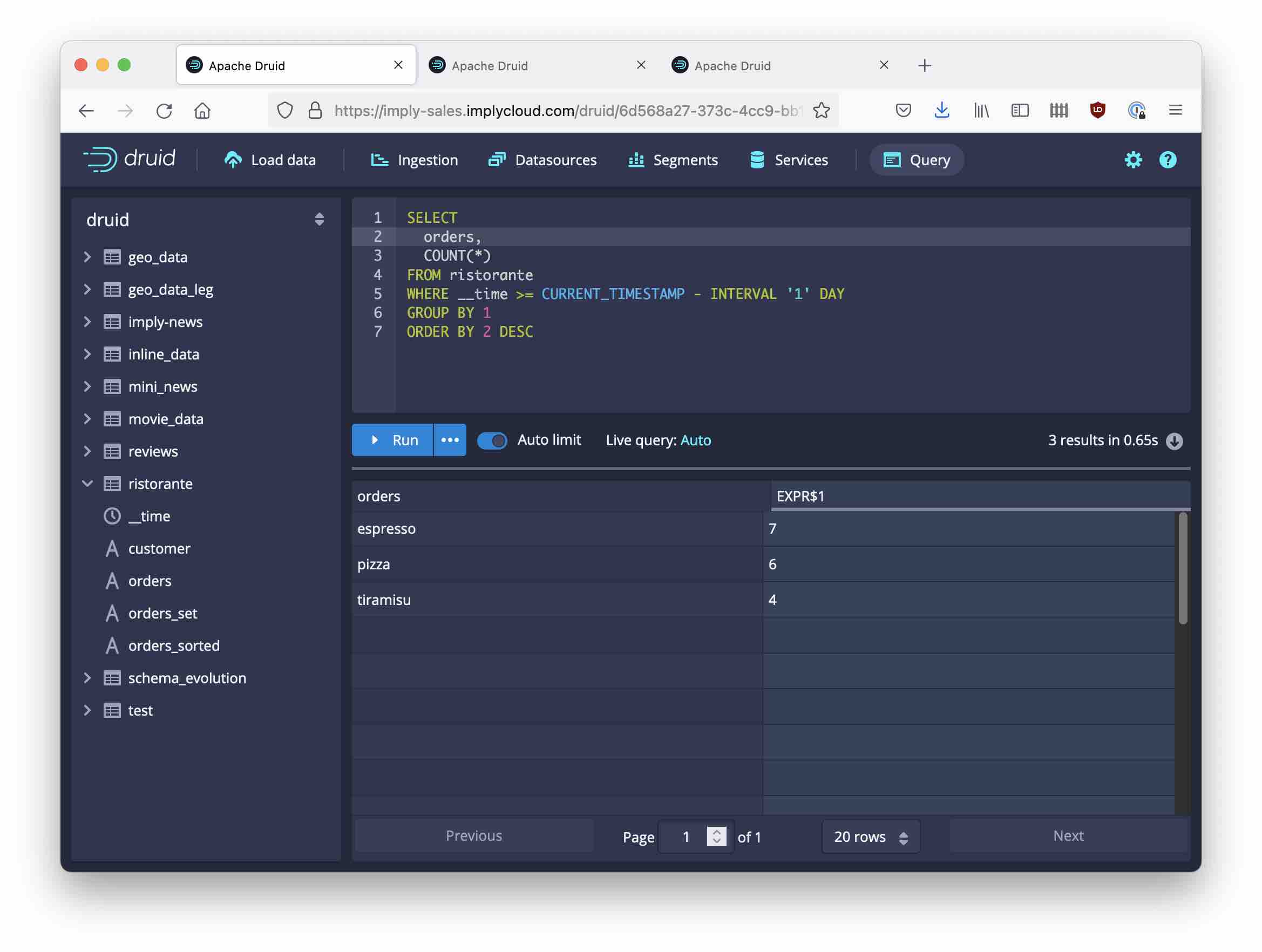
For this query, I use the unsorted ARRAY representation of the orders dimension. While it does not really matter here, it is worth noting that “unsorted” means “preserve whichever order the data came in”.
How many distinct customer visits ordered each dish?
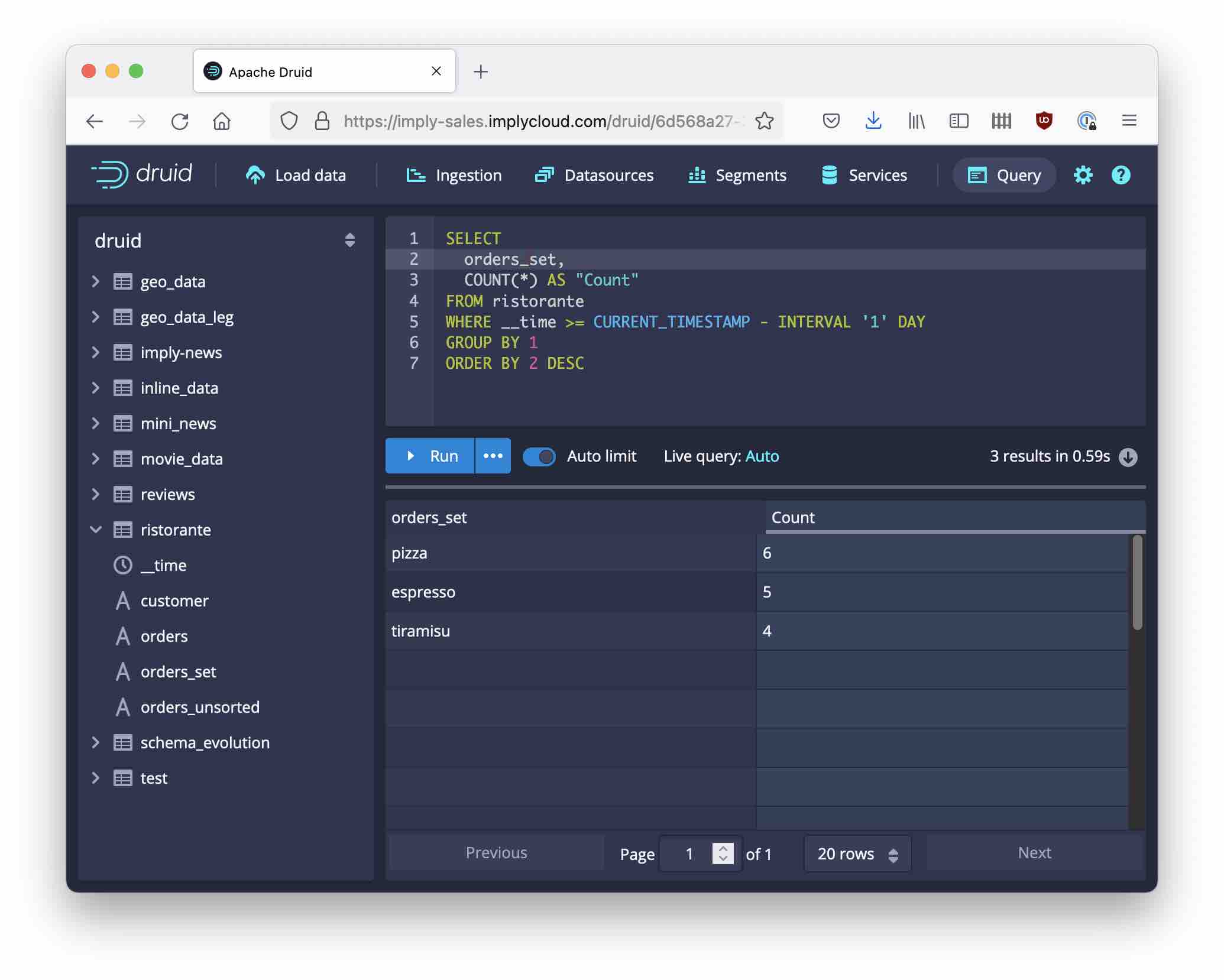
I answer this question using the SORTED_SET handling.
Note: A multi-value dimension exhibits special behavior in GROUP BY queries. It is counted as if there is a row for each field in the multi-value dimension.
More advanced queries
What if we have different questions? Like:
- How many customers had the same items ordered (but not necessarily in the same order)
- How many customers had the exact same menu sequence?
We can do this; but for those queries, we need to aggregate the orders into a string. Let’s find out how to do this.
There are various functions in Druid to handle multi-value dimensions. Do not confuse them with aggregation functions that operate on the result of a GROUP BY query, like ARRAY_AGG or the new STRING_AGG. Those are not what we need here. They may be interesting to look at in one of the next posts, though.
Instead, let’s look at the multi-value functions, those are the ones starting with MV_.
Specifically, MV_TO_STRING concatenates all the values in a multi-value column using a configurable delimiter. So,
MV_TO_STRING(orders_sorted, ',')returns the (alphabetically) ordered list of all items that each customer ordered, including double orders. This enables me to compare or aggregate customers that had the exact same menu basket including repeated items.MV_TO_STRING(orders_set, ',')returns the menu basket for each customer, not counting items. With this I can do cross selling analytics.MV_TO_STRING(orders, ',')lets me compare the customer journey of each customer in original order (by time). This unlocks timeline and customer journey analytics.
Here we go:
How many customers had the exact same items and number of items?
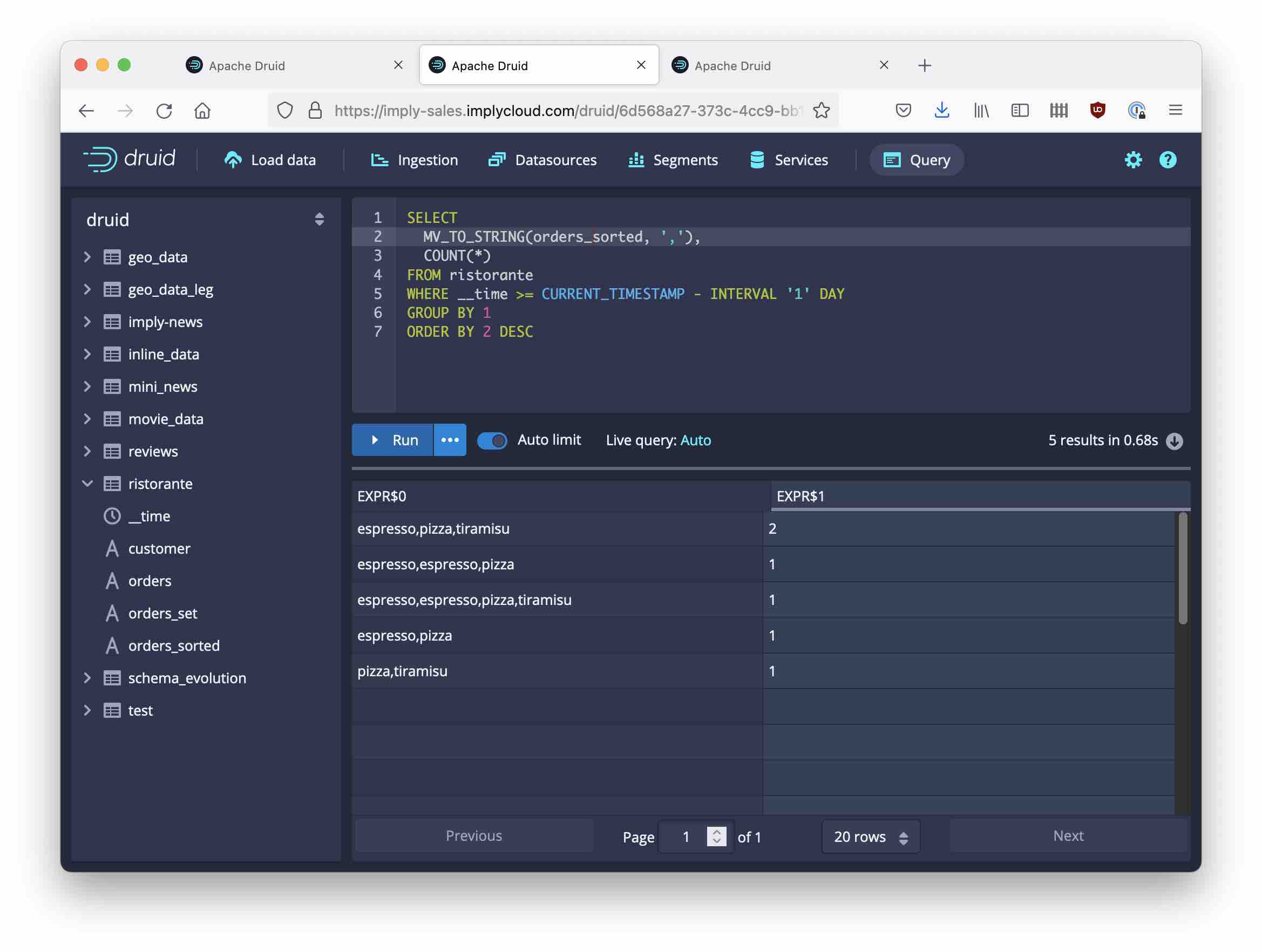
How many customers had the exact same items but maybe a different count?
(When we don’t care about the second espresso)
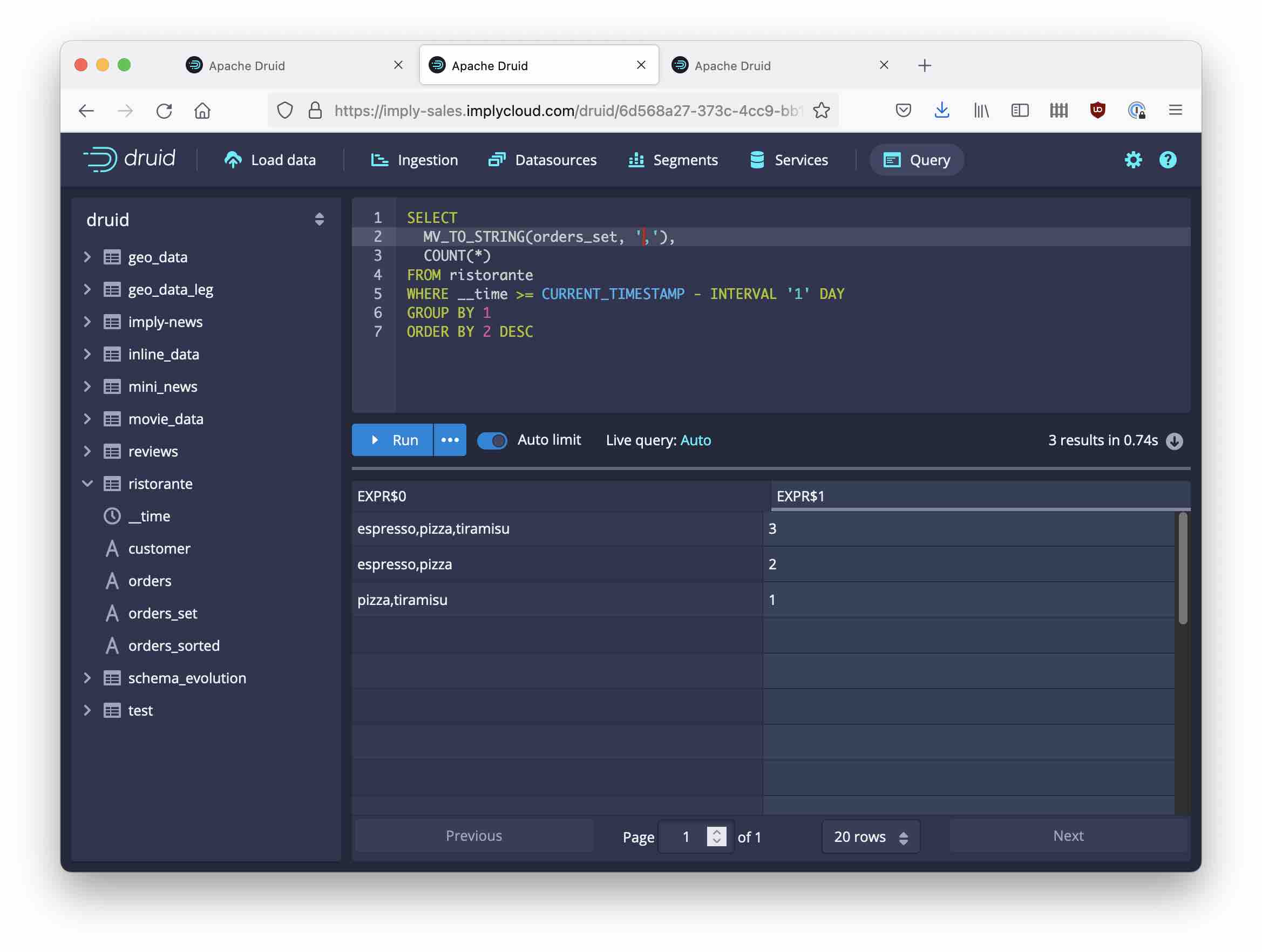
How many customers had the exact same sequence of orders?
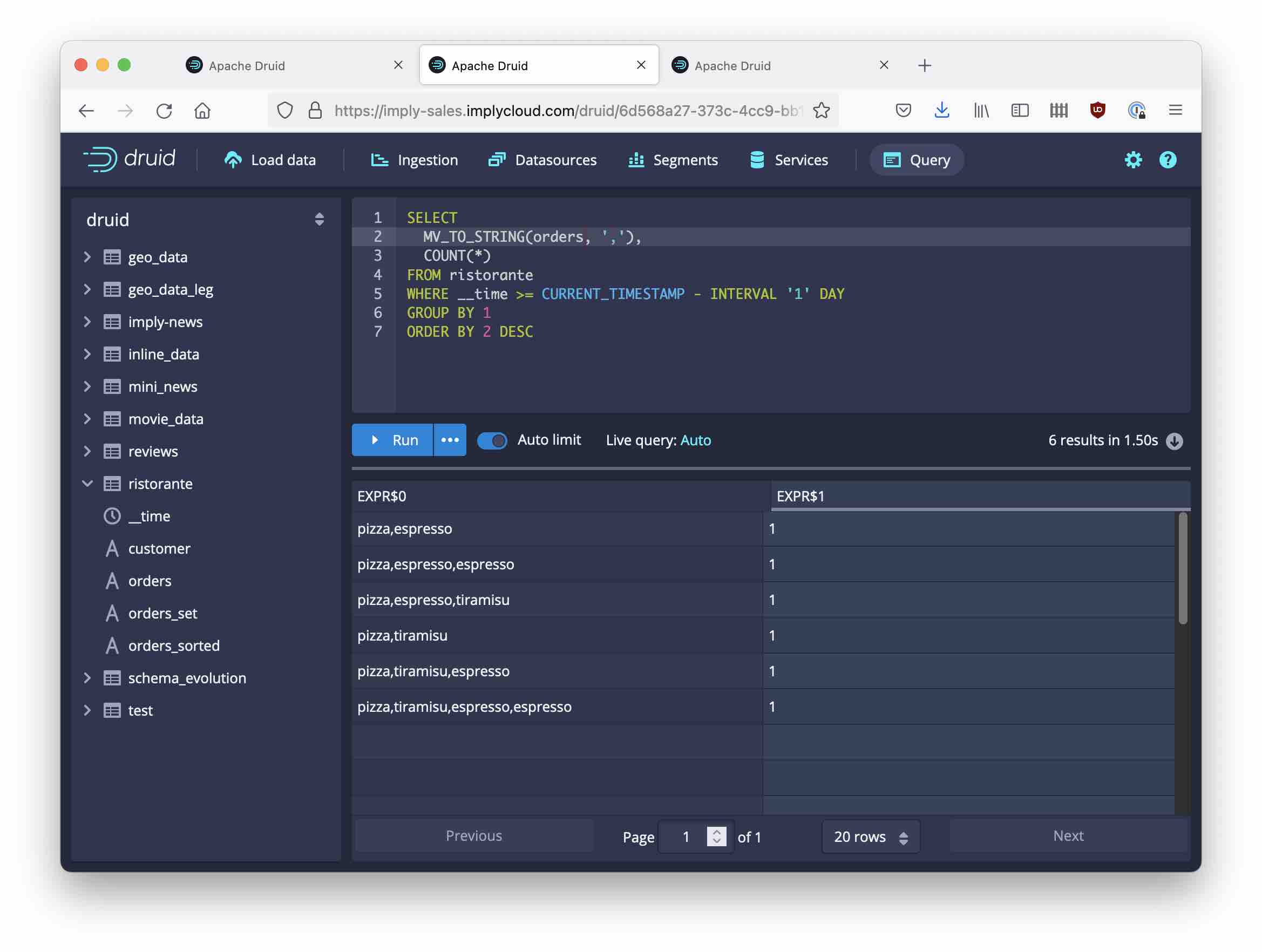
Learnings
- Multi-value handling strategy can enable a lot of interesting analytics use cases.
- Use unsorted arrays if you want to keep the original order of items.
- Don’t confuse array aggregation functions and multi-value functions.
Next time, let’s find out not only how many orders matched a certain list, but also who were the customers behind these orders. Here, the STRING_AGG function will come in handy. See you then!