Multi-Value Dimensions in Apache Druid (Part 2)
This is part 2 of a miniseries about multi-value dimensions in Apache Druid. More posts can be found here:
Let’s continue our journey into the world of multi-value dimensions in Apache Druid - with this here:
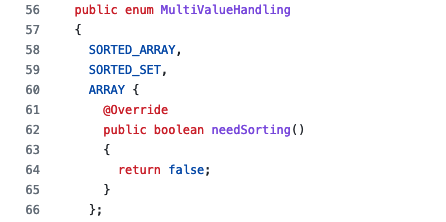
Multi-Value Handling!
Remember the casual remark from last time about this here:
By default, a multi-value dimension is represented as a sorted array, but there are alternatives. Let’s look at them in a bit more detail. Using the data sample from the movie-tags tutorial, let’s create some copies of our tags dimension. This is conveniently done in the Transform stage of the ingestion wizard, just by defining new dimensions and referencing the original field as the expression:
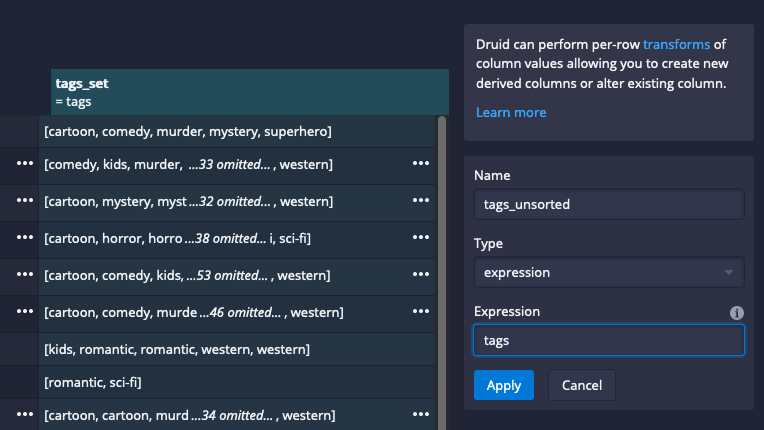
Define two additional dimensions tags_unsorted and tags_set. Proceed through the Filter step to Configure schema.
It is possible that you do not see the new fields now. Flip the automatic schema detection switch off and on again

and you should see them all.
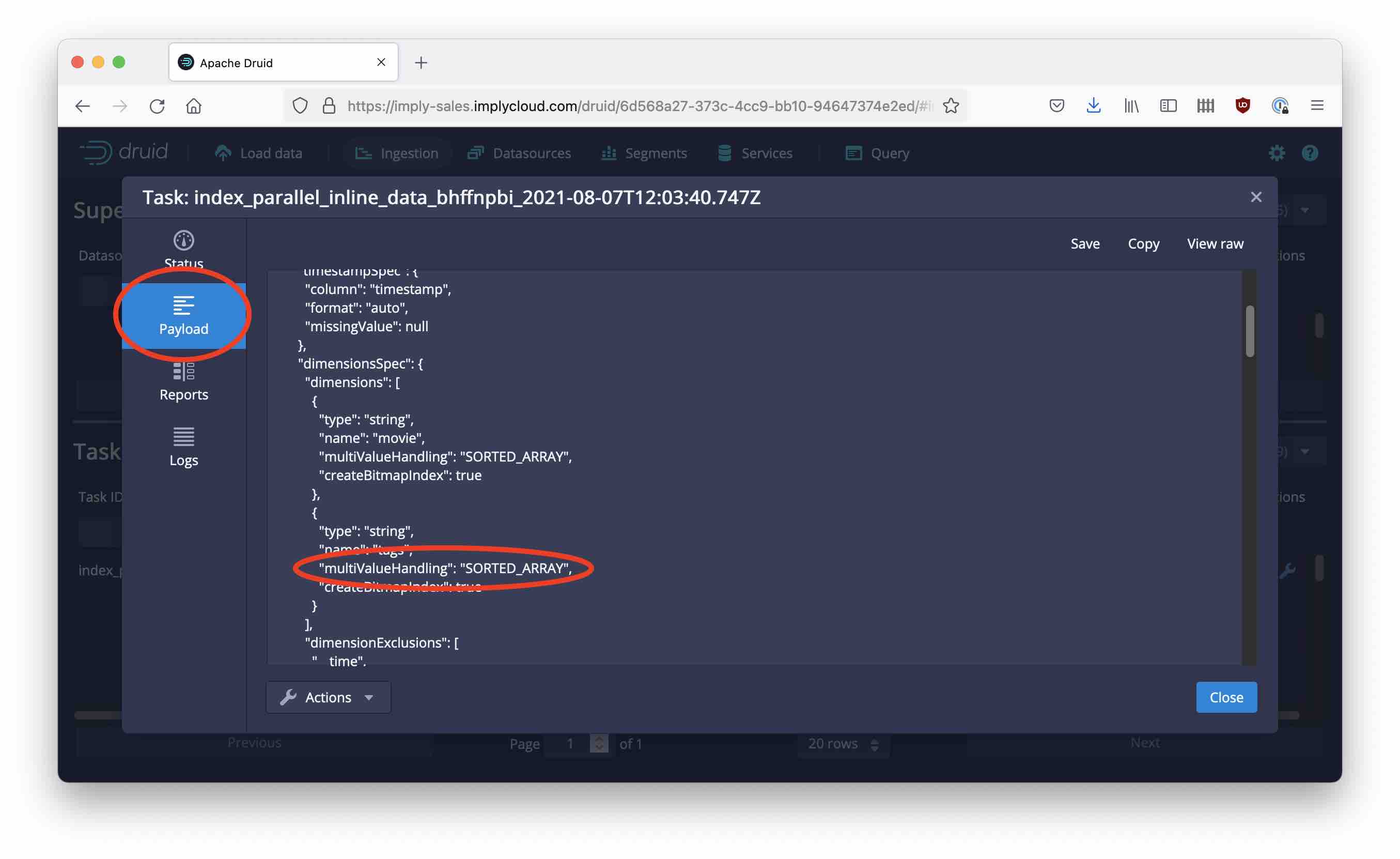
Continue like last time until the Edit spec stage. Find the "dimensionsSpec" part and replace it with this snippet:
"dimensionsSpec": {
"dimensions": [
{
"type": "string",
"name": "movie",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "tags",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "tags_unsorted",
"multiValueHandling": "ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "tags_set",
"multiValueHandling": "SORTED_SET",
"createBitmapIndex": true
}
],
"dimensionExclusions": [
"__time",
"timestamp"
]
},
Submit the ingestion job and see what you get:
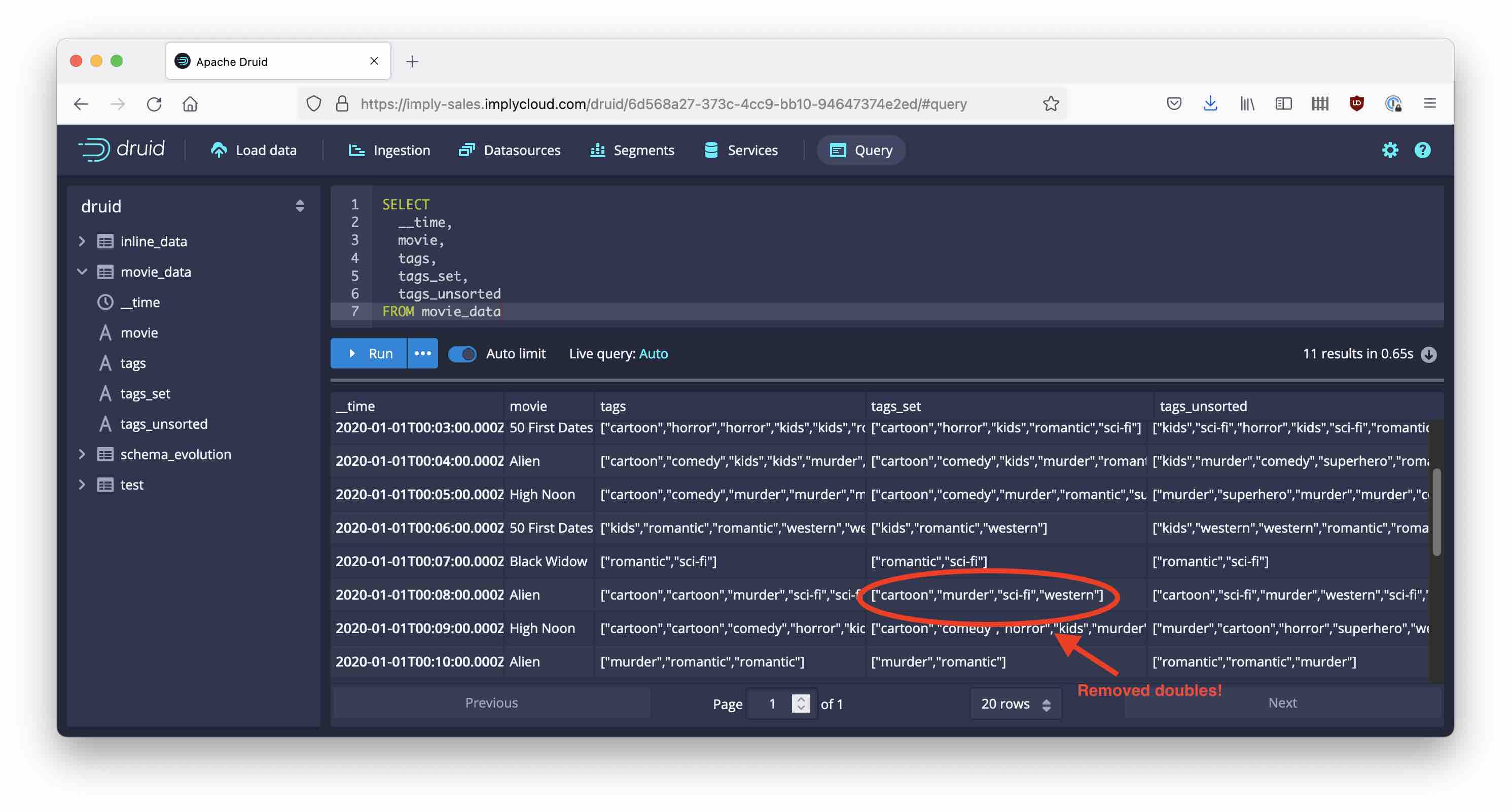
This is great when you need to deduplicate tag values.
Learnings
- By default, multi-value dimensions are represented as sorted arrays.
- Alternatives are unsorted arrays and sets.
- Sets are especially neat because they have deduplication built in.
- As of now, you need to specify the handling manually in the JSON spec.
- Documentation of this feature is somewhat terse, although it is going to improve soon.