Table Based Lookups in Imply Polaris
Imply’s Polaris service has a new feature: Lookups. Lookups in Polaris provide a convenient way to model dimension tables in a star schema, and they are more flexible and less resource hungry than the lookups you know from open source Druid. Let’s take a closer look!
Recap: Lookups in Apache Druid
Druid lookups are cached key-value maps that are kept in memory on all historical and peon processes. I wrote about them in an earlier blog. A lookup can be queried like a table, but it has only two columns - key k and value v. If you want to lookup multiple values for a key - say, a customer’s name, street address, city, and country - then you need to create a separate lookup for each.
Lookups can be populated in various ways:
- you can upload the map data directly via the API or the Druid console
- or you can populate a lookup from a file described by a URL
- or from a Kafka topic
- or from a database table.
The last option is particularly interesting because the source of the lookup can also be a regular Druid table, if you specify Druid’s Avatica driver in the JDBC URL. This works but is kind of a hack, and has limited flexibility. But it is how we used to set up lookups in Polaris in the backend, before they were officially supported.
Lookups based on Druid Segments
With the September release, users can configure their own lookups in Polaris. These lookups are built directly on top of Polaris tables, and they are different from all other types of lookups. These segment based lookups are now available in Polaris by default, although they can be enabled in Imply Hybrid and Imply Enterprise by installing a specific extension that is part of the commercial software release of Imply.
The big advantage of segment based lookups: any (string) column can be either key or value. This means the address example above could be implemented using just one lookup structure. Segment based lookups are also more memory efficient, and by being integrated with the Polaris (or Druid) table schema the entire structure becomes more maintainable.
How to do it in practice
Let’s look at a practical example. We are going to generate a data set that has ISO country codes in it, and we want to enrich these data with country names by means of a lookup list you can download here.
Then generate some data using this little script:
import json
import time
from faker import Faker
fake = Faker()
location_fields = ["latitude", "longitude", "place_name", "two-letter_country_code", "timezone"]
for i in range(100):
place = fake.location_on_land()
rec = dict(zip(location_fields, place))
rec["timestamp"] = int(time.time())
print(json.dumps(rec))
and run it like so:
python3 ./gendata.py >data.json
And upload those two files as data sources to Polaris.
Modeling the dimension table and the lookup
The dimension table has to fulfill a few requirements to be eligible as a lookup source:
- all fields that you want to use in the lookup have to be string columns
- the table has to be
PARTITIONED BY ALL - and it has to fit in a single segment (it should be less than 4GB in size).
So, when ingesting the data from all.csv into table countries:
- Make sure to lock every column into a declaration as string. In Polaris, by default all table columns have a type of
Auto, but you can override this by declaring the respective column explicitly.
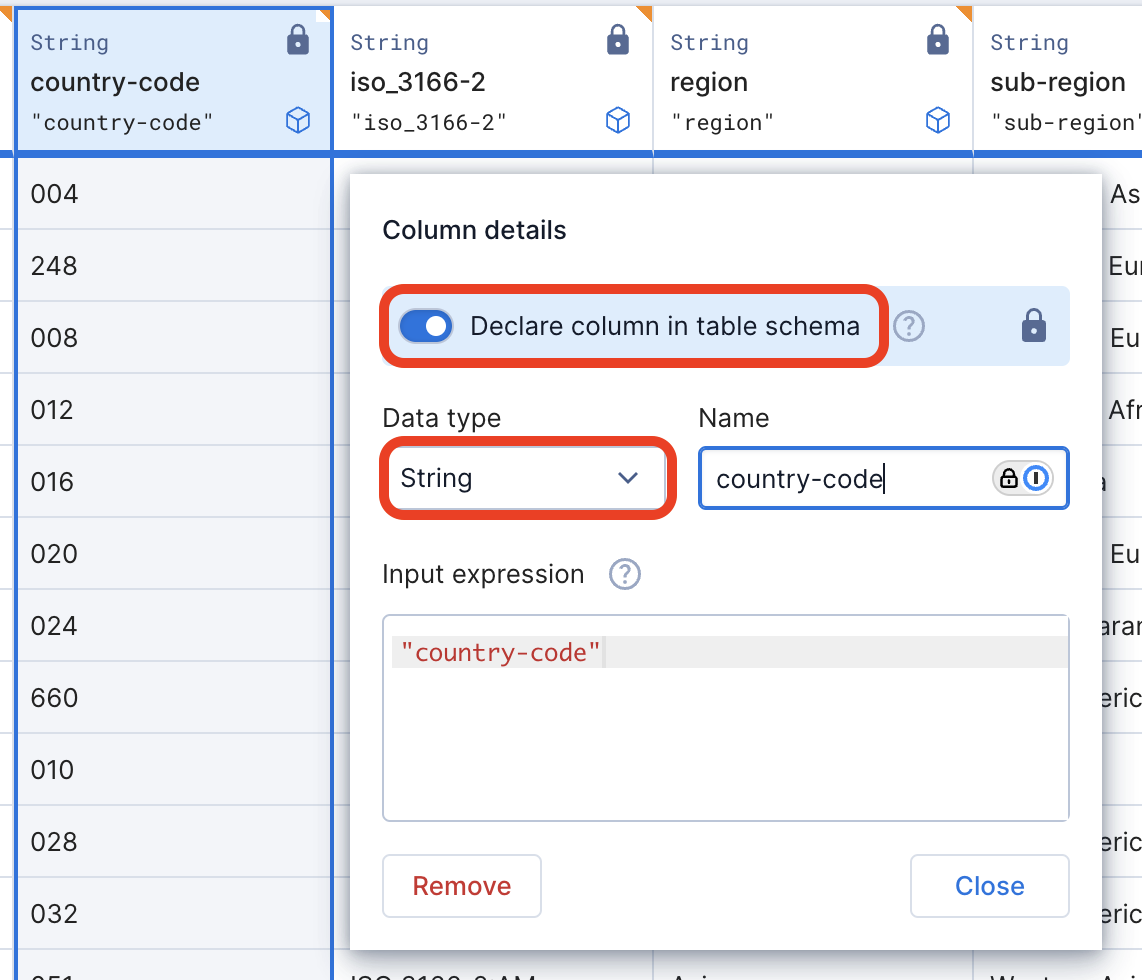
- The table has to be partitioned by All Time, which means no time partitioning is applied. If you partition by anything other than
All, you will not be able to select that table for a lookup.
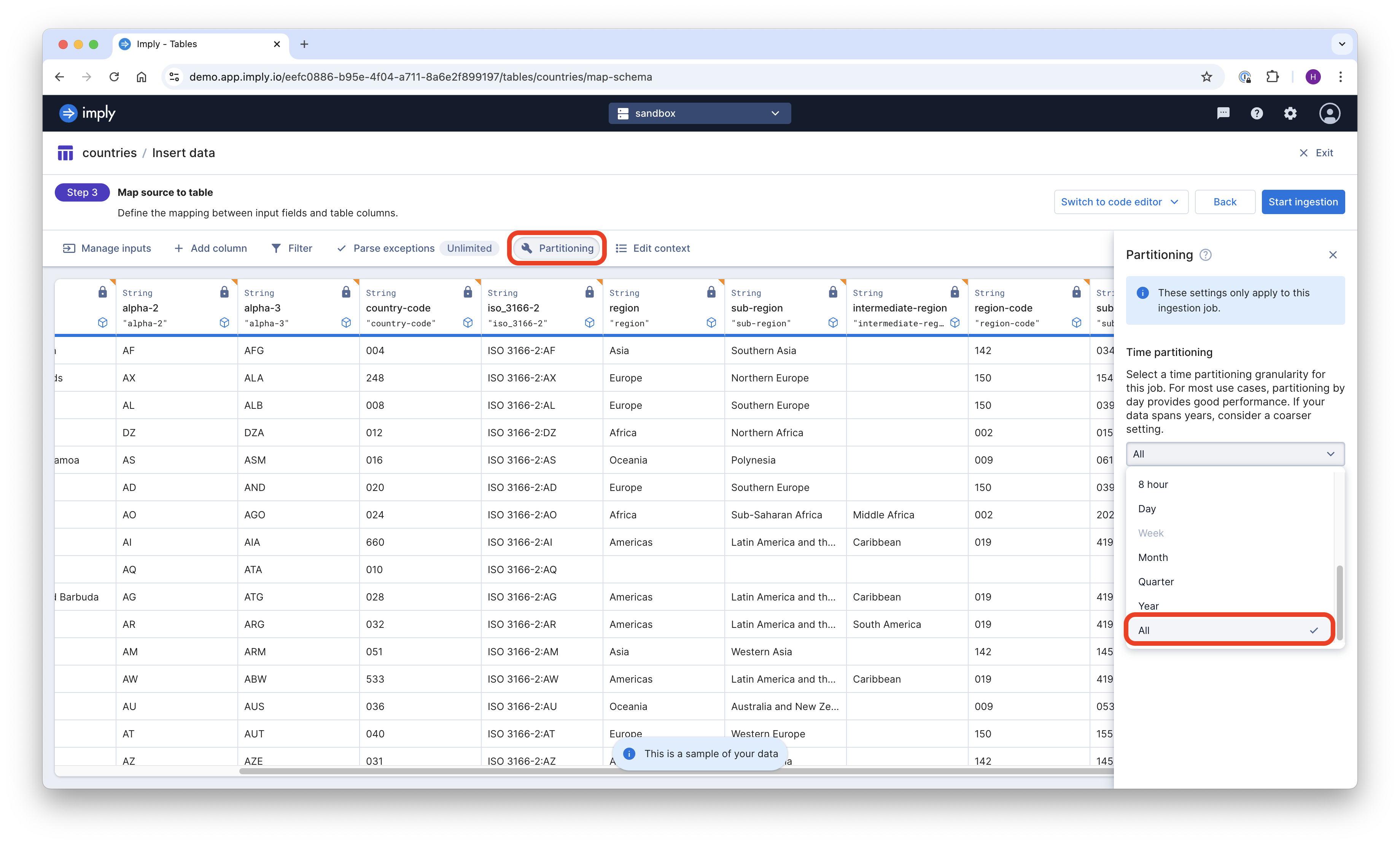
- Leave the timestamp as Current time. For a dimension table, this is a dummy anyway.
In the left navigation menu, you will find the new item Lookups. Navigate there and select the countries table from the dropdown menu.
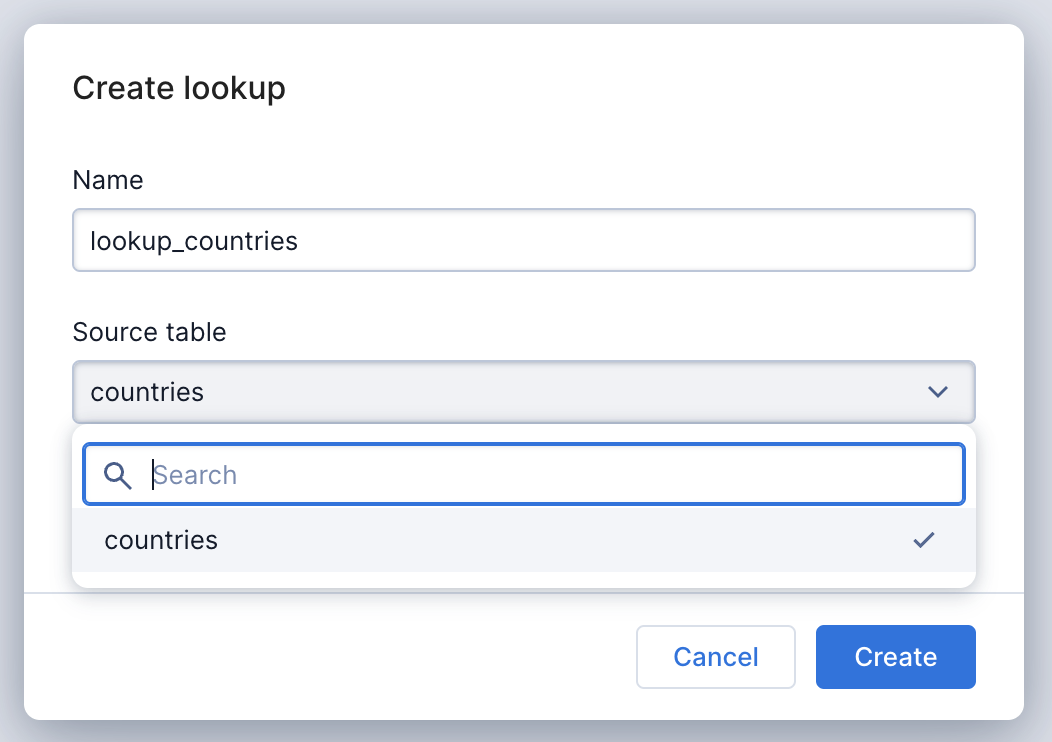
That’s the entire configuration!
Modeling the fact table
The fact table is a regular Polaris table. Just make sure the (foreign) key column (the one you want to apply the lookup to) is a string too or else you will need a cast in the lookup. Polaris expects the key and value fields both to be strings, otherwise the LOOKUP call fails.
How to query data using lookups
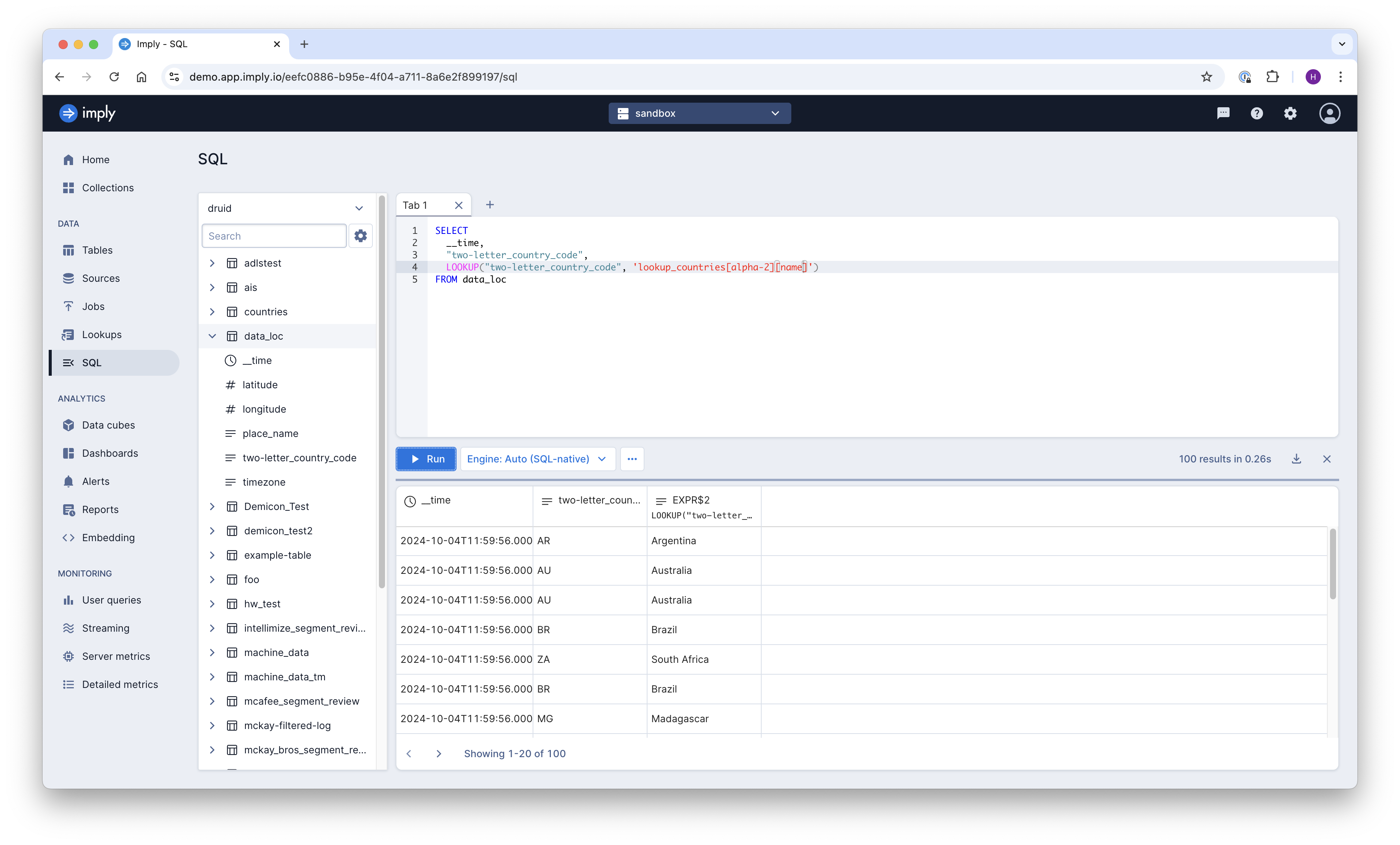
Compared to regular Druid lookups, the syntax has been extended. In addition to the lookup name, you specify the key and value columns in square brackets using the syntax
LOOKUP(..., 'lookup_name[key_column][value_column]')
For the example table, this query will do nicely:
SELECT
__time,
"two-letter_country_code",
LOOKUP("two-letter_country_code", 'lookup_countries[alpha-2][name]')
FROM data_loc
You can run this in Polaris’s SQL workbench:
How to visualize lookup data in Pivot
When creating a datacube in Polaris, use the LOOKUP(..., 'lookup_name[key_column][value_column]') syntax in dimension definitions. Don’t forget the t. prefix to refer to the main table:
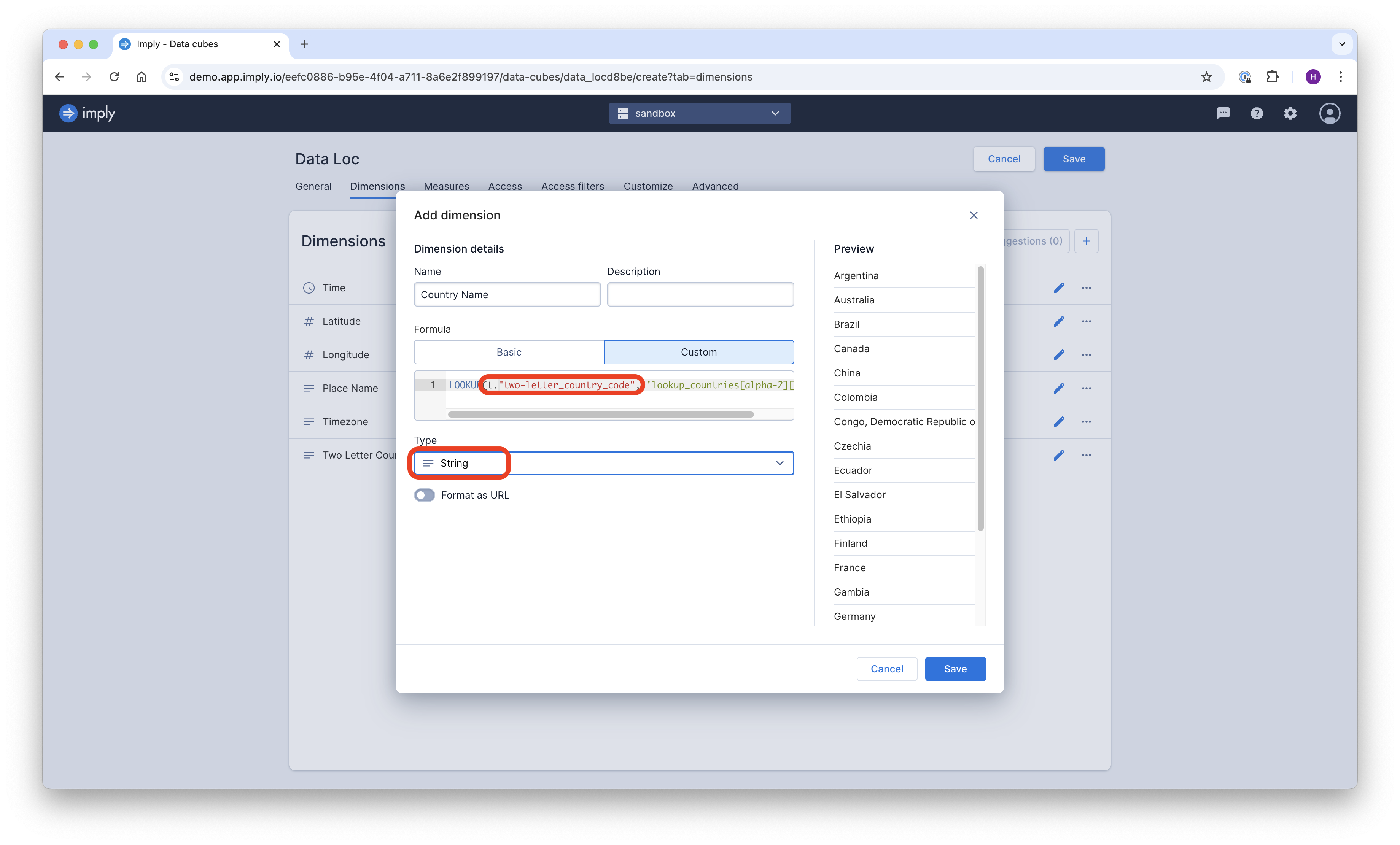
Side note: unlike a regular Kimball model, you can also model measures by aggregating over a LOOKUP expression. You will, however, have to store the measure data as strings and cast them to numbers in the final aggregation expression.
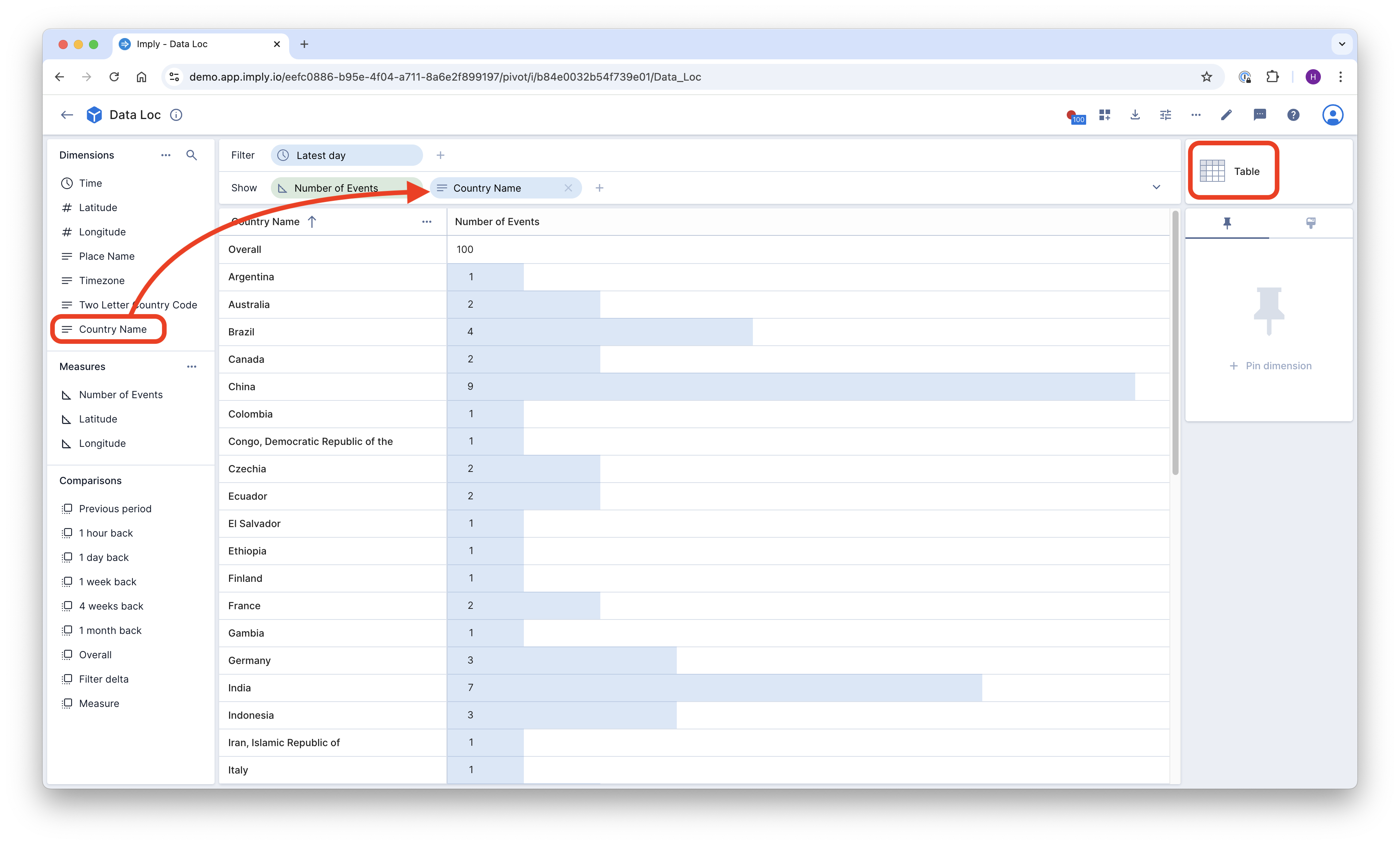
And with that, you can use the lookup values in any visualization:
Conclusion
- Polaris (and the commercial releases of Imply) offer a new flavor of lookups based on single segment tables.
- In segment based lookups, any column can be a key or a value.
- This is very convenient for star schema-style dimension tables.