Druid Data Cookbook: Flattening Arrays of Complex Objects

A common problem in data that we ingest into Druid is that we may encounter arrays of nested objects, and we want to reason about specific fields within those objects. For instance, assume we have various teams for some sort of contest, and the members of a team might be represented like so:
[
{
"name": "Alice",
"gender": "F"
},
{
"name": "Bob",
"gender": "M"
},
{
"name": "Carol",
"gender": "F"
}
]
Each member has a name and some other attributes. But what if I want to get a list of all the teams that Bob is a member of? I’d need to extract an array of the relevant subfields only. How do I do this in Druid?
The naïve approach would be to write some expression like JSON_VALUE("members", '$[*].name'). Unfortunately, Druid does not support wildcard syntax in JSONPath expressions. So if seems that we are stuck. Or are we?
Loading some data
For this tutorial, download a fresh copy of Druid 30. Run a local quickstart instance and ingest this data set:
timestamp|team|members
2024-09-01|Team 1|[{ "name": "Alice", "gender": "F" }, { "name": "Bob", "gender": "M" }, { "name": "Carol", "gender": "F" }]
2024-09-01|Team 2|[{ "name": "Dan", "gender": "M" }, { "name": "Eve", "gender": "F" }, { "name": "Frank", "gender": "M" }]
If you use the SQL wizard, choose the TSV parser and set the separator character to |. Also, make sure that you add the PARSE_JSON function to the expression for the members column:
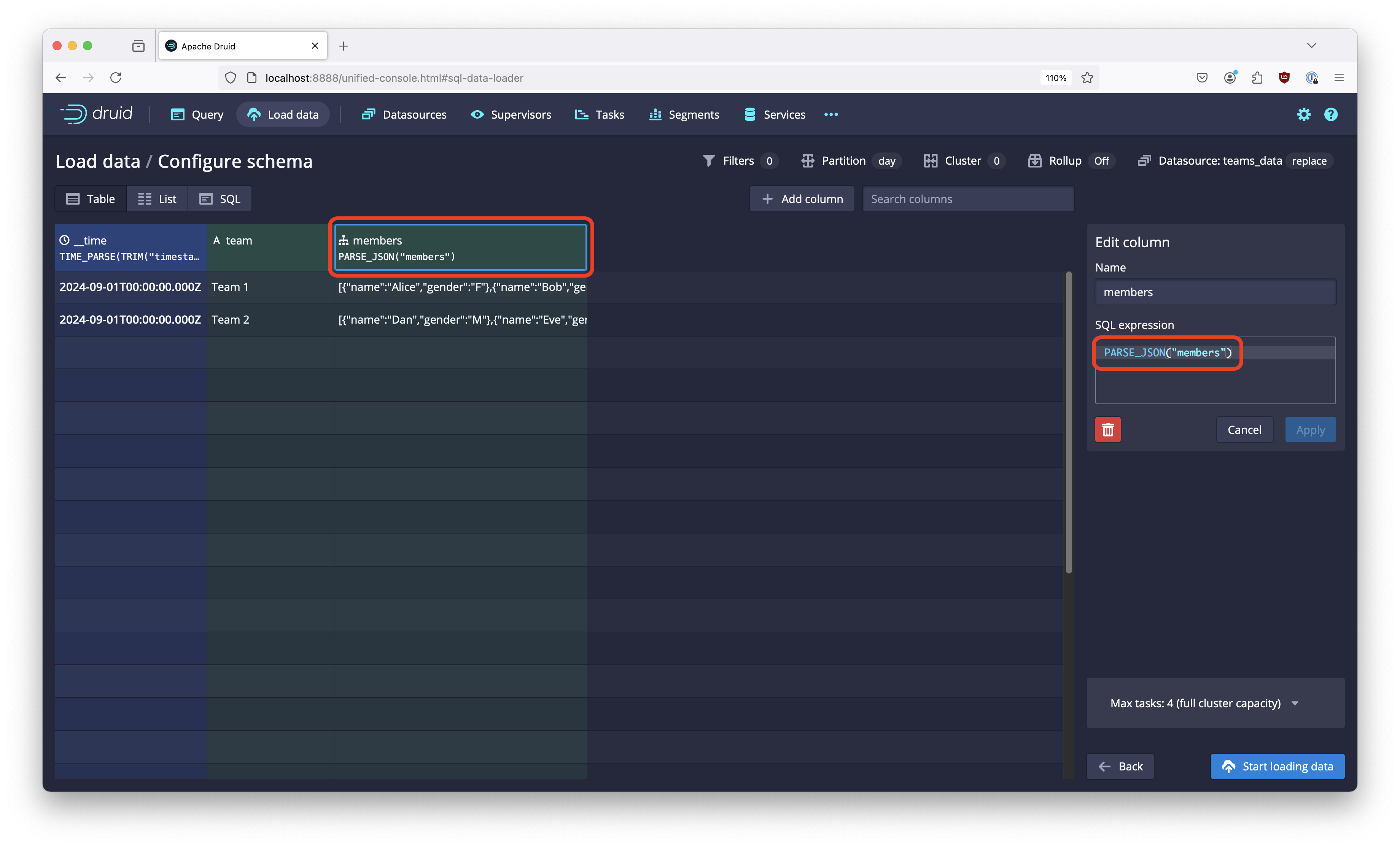
Or just use this SQL:
REPLACE INTO "teams_data" OVERWRITE ALL
WITH "ext" AS (
SELECT *
FROM TABLE(
EXTERN(
'{"type":"inline","data":"timestamp|team|members\n2024-09-01|Team 1|[{ \"name\": \"Alice\", \"gender\": \"F\" }, { \"name\": \"Bob\", \"gender\": \"M\" }, { \"name\": \"Carol\", \"gender\": \"F\" }]\n2024-09-01|Team 2|[{ \"name\": \"Dan\", \"gender\": \"M\" }, { \"name\": \"Eve\", \"gender\": \"F\" }, { \"name\": \"Frank\", \"gender\": \"M\" }]"}',
'{"type":"tsv","delimiter":"|","findColumnsFromHeader":true}'
)
) EXTEND ("timestamp" VARCHAR, "team" VARCHAR, "members" VARCHAR)
)
SELECT
TIME_PARSE(TRIM("timestamp")) AS "__time",
"team",
PARSE_JSON("members") AS "members"
FROM "ext"
PARTITIONED BY DAY
Querying the data
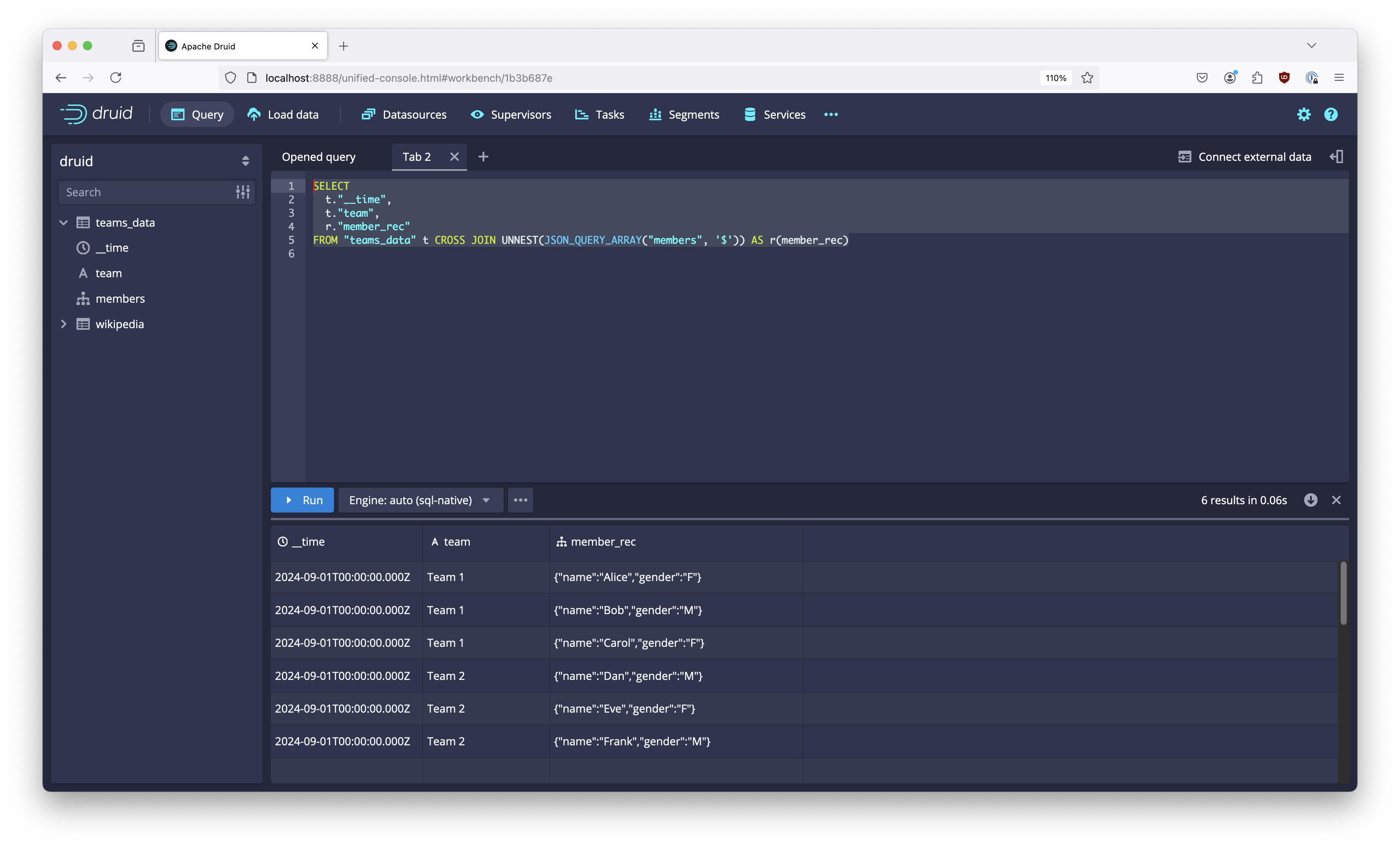
Let’s first unnest the members data into individual rows. Unfortunately, we cannot just apply UNNEST("members"). This is because Druid has no way of knowing that the value of members is always an array. In an earlier post I described the problem and how to solve it using JSON_QUERY_ARRAY:
SELECT
t."__time",
t."team",
r."member_rec"
FROM "teams_data" t CROSS JOIN UNNEST(JSON_QUERY_ARRAY("members", '$')) AS r(member_rec)
Use this query as a common table expression and group the values back in the main query:
WITH cte AS (
SELECT
t."__time",
t."team",
r."member_rec"
FROM "teams_data" t CROSS JOIN UNNEST(JSON_QUERY_ARRAY("members", '$')) AS r(member_rec)
)
SELECT team, ARRAY_AGG(JSON_VALUE(member_rec, '$.name')) AS member_names
FROM cte
GROUP BY team
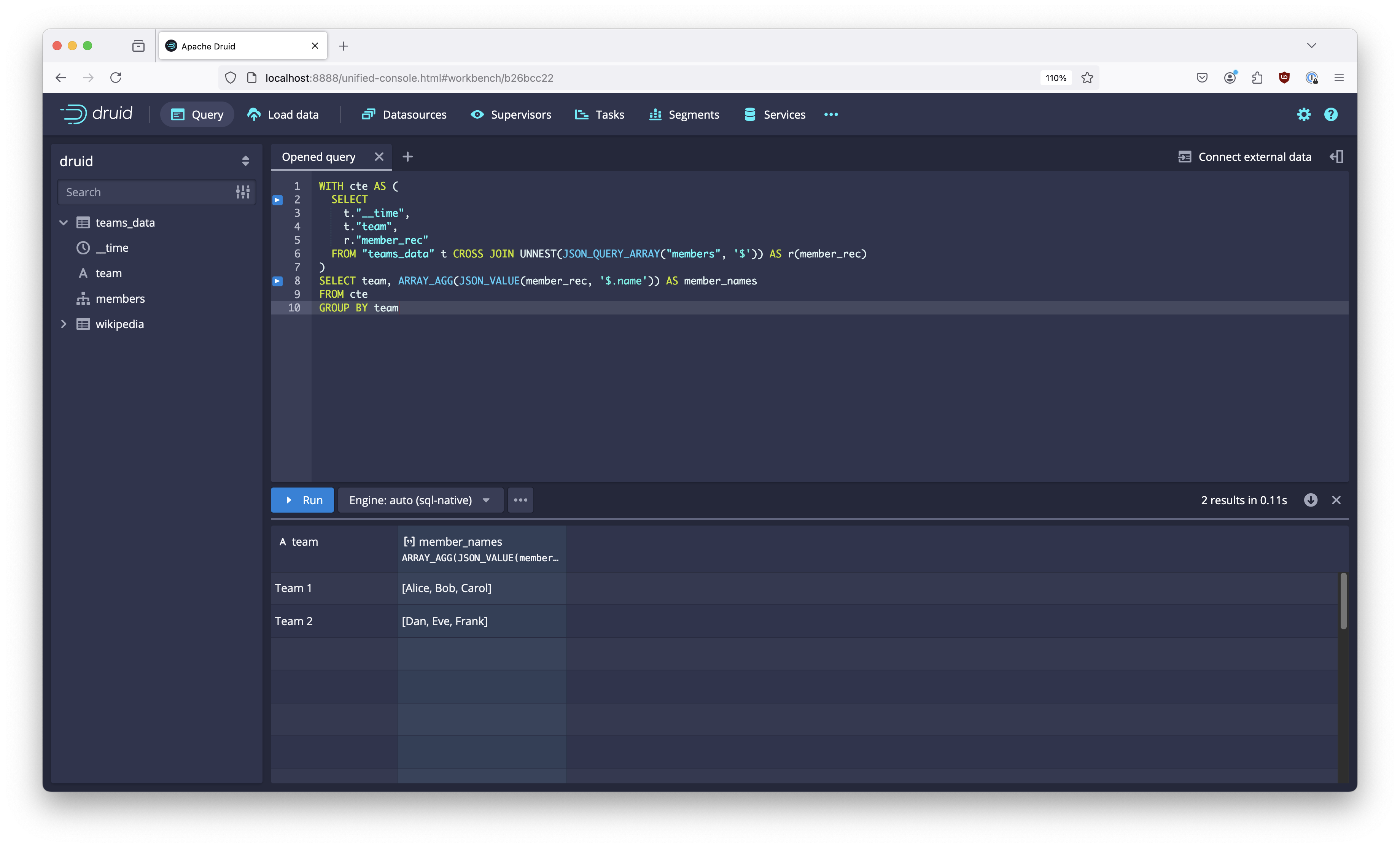
As you can see, this query yields a list of member names for each team - just what we wanted to get.
This technique is even more powerful when used in conjunction with JSON_PATHS to extract leaf objects at any level of the hierarchy. But I will leave that for another blog post.
Conclusion
- In order to flatten and extract scalar fields from arrays of complex objects, you can transpose them using the
UNNESTfunction. - Advanced filtering can be done on the single row level.
- Then group the values back together and use
ARRAY_AGGto reconstitute the arrays.
“This image is taken from Page 500 of Praktisches Kochbuch für die gewöhnliche und feinere Küche” by Medical Heritage Library, Inc. is licensed under CC BY-NC-SA 2.0 ![]()
![]()
![]()
![]() .
.