New in Apache Druid 27: Querying Deep Storage
In realtime analytics, a common scenario is that you want to retain a lot of (years of) historical data in order to run analytics over a longer period of time. But these analytical queries occur infrequently and their performance is usually not critical. The bulk of everyday queries, however, accesses only a limited set of relatively fresh data, typically 1 or 2 weeks worth.
In the standard configuration of Druid, until recently you would have to preload all data that you wanted to be queryable to your data servers. That would mean a lot of local storage would be required, most of which would be accessed very rarely. You could mitigate this problem to a certain extent using data tiering, but the cost associated with just having that storage around would still be considerable.
Druid 27 comes with the ability to query deep storage directly, meaning in the above scenario you can actually keep only your 1-2 weeks of fresh data on local SSDs and retain all your historical data in deep storage only. Because of the higher latency of cloud storage, deep storage queries are generally executed asynchronously, and there is a new API endpoint just for deep storage queries.
Let’s run a small example to learn how deep storage query is configured and used!
This tutorial works with the Druid 27 quickstart.
Building the test data set
Ingest the wikipedia example data set. We want to have a bunch of segments so let’s partition by hour. You can configure the ingestion job using the wizard, or just use this SQL statement:
REPLACE INTO "wikipedia" OVERWRITE ALL
WITH "ext" AS (SELECT *
FROM TABLE(
EXTERN(
'{"type":"http","uris":["https://druid.apache.org/data/wikipedia.json.gz"]}',
'{"type":"json"}'
)
) EXTEND ("isRobot" VARCHAR, "channel" VARCHAR, "timestamp" VARCHAR, "flags" VARCHAR, "isUnpatrolled" VARCHAR, "page" VARCHAR, "diffUrl" VARCHAR, "added" BIGINT, "comment" VARCHAR, "commentLength" BIGINT, "isNew" VARCHAR, "isMinor" VARCHAR, "delta" BIGINT, "isAnonymous" VARCHAR, "user" VARCHAR, "deltaBucket" BIGINT, "deleted" BIGINT, "namespace" VARCHAR, "cityName" VARCHAR, "countryName" VARCHAR, "regionIsoCode" VARCHAR, "metroCode" BIGINT, "countryIsoCode" VARCHAR, "regionName" VARCHAR))
SELECT
TIME_PARSE("timestamp") AS "__time",
"isRobot",
"channel",
"flags",
"isUnpatrolled",
"page",
"diffUrl",
"added",
"comment",
"commentLength",
"isNew",
"isMinor",
"delta",
"isAnonymous",
"user",
"deltaBucket",
"deleted",
"namespace",
"cityName",
"countryName",
"regionIsoCode",
"metroCode",
"countryIsoCode",
"regionName"
FROM "ext"
PARTITIONED BY HOUR
You should end up with 22 segments, each spanning an hour.
Recap: Retention rules
By default, Druid retains all data in deep storage that it has ever ingested. You have to run an explicit kill task to delete data permanently.
However, standard Druid queries can only work with data segments that have been preloaded to the data servers. Preloading of data is configured using retention rules, which you can configure on a per-datasource basis. Retention rules are evaluated for each segment, from top to bottom, until a rule is found that matches the segment in question. Each rule is either a Load rule (which tells the Coordinator to make that segment available for queries), or a Drop rule (which removes the segment from the list of available segments.) Rules specify either a time period (relative to the current time), or an absolute time interval.
In production setups you would usually find period rules (“retain only data for the last 2 weeks”), but for the tutorial we are going to use interval rules because we are working with a fixed dataset.
First attempt to configure deep storage query
The data sample includes one day’s worth of data. Let’s load all data from noon onward, and drop all data from before noon, and see if we can query the data using the endpoint for deep storage.
Here is the first set of retention rules:
[
{
"interval": "2016-06-27T12:00:00.000Z/2020-01-01T00:00:00.000Z",
"tieredReplicants": {
"_default_tier": 2
},
"useDefaultTierForNull": true,
"type": "loadByInterval"
},
{
"type": "dropForever"
}
]
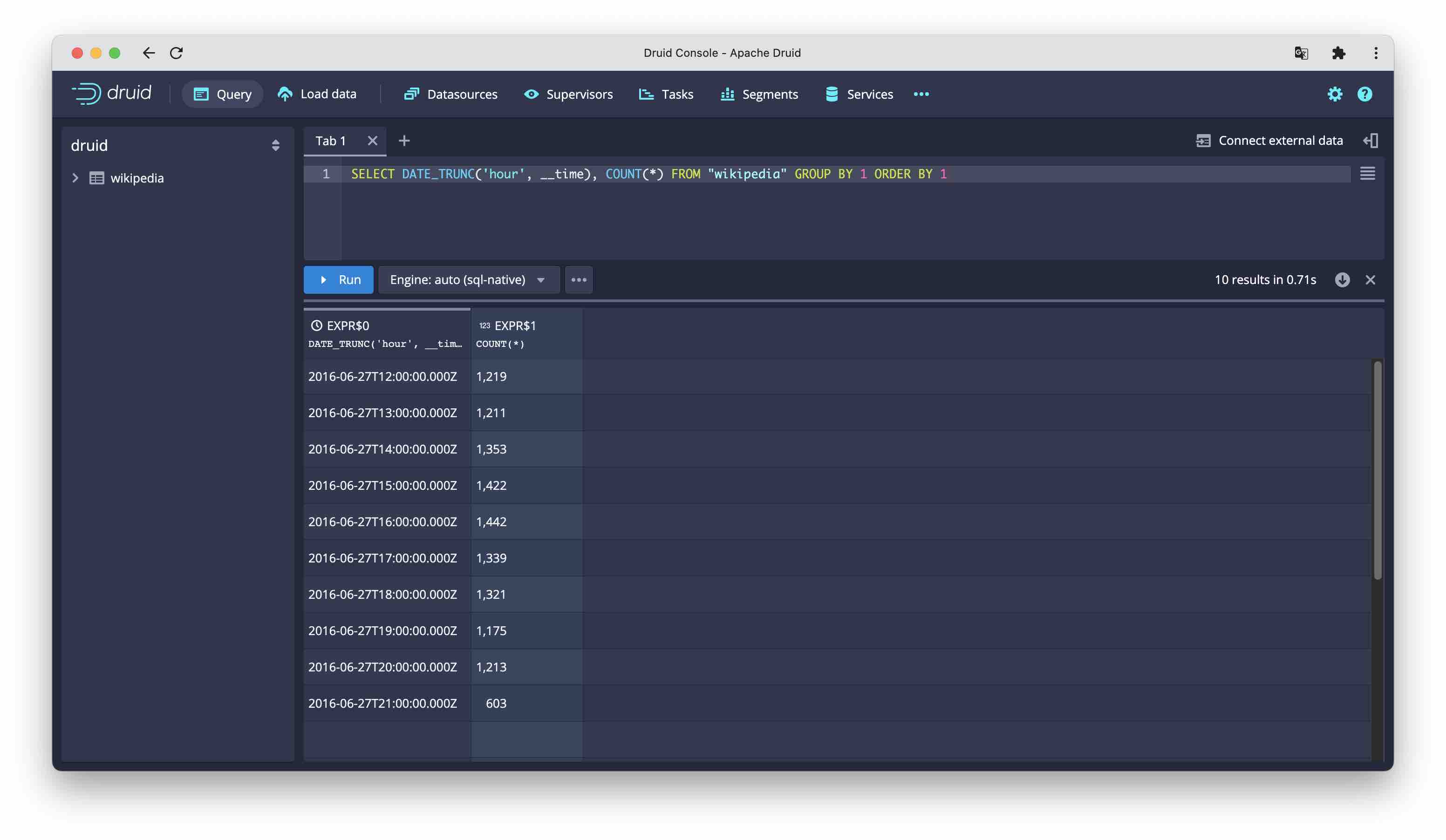
If you run a standard query in the console, you see that the rules have been applied:
Using curl, I am sending the same query to the endpoint for deep storage query:
curl -L -H 'Content-Type: application/json' localhost:8888/druid/v2/sql/statements -d'{
"query": "SELECT DATE_TRUNC('\''hour'\'', __time), COUNT(*) FROM \"wikipedia\" GROUP BY 1 ORDER BY 1",
"context":{
"executionMode":"ASYNC"
}
}'
{"queryId":"query-db8b79ae-f28b-466e-b876-3f987d0e87fc","state":"ACCEPTED","createdAt":"2023-09-06T11:33:39.839Z","schema":[{"name":"EXPR$0","type":"TIMESTAMP","nativeType":"LONG"},{"name":"EXPR$1","type":"BIGINT","nativeType":"LONG"}],"durationMs":-1}
This is an asynchronous endpoint - it returns immediately and hands me back a query ID. I have to append the query ID to the URL in order to poll the status and eventually get the result:
curl -L -H 'Content-Type: application/json' localhost:8888/druid/v2/sql/statements/query-db8b79ae-f28b-466e-b876-3f987d0e87fc
{"queryId":"query-db8b79ae-f28b-466e-b876-3f987d0e87fc","state":"SUCCESS","createdAt":"2023-09-06T11:33:39.839Z","schema":[{"name":"EXPR$0","type":"TIMESTAMP","nativeType":"LONG"},{"name":"EXPR$1","type":"BIGINT","nativeType":"LONG"}],"durationMs":13944,"result":{"numTotalRows":10,"totalSizeInBytes":374,"dataSource":"__query_select","sampleRecords":[[1467028800000,1219],[1467032400000,1211],[1467036000000,1353],[1467039600000,1422],[1467043200000,1442],[1467046800000,1339],[1467050400000,1321],[1467054000000,1175],[1467057600000,1213],[1467061200000,603]],"pages":[{"id":0,"numRows":10,"sizeInBytes":374}]}}
Oops. We got the same ten rows as from the interactive query. The naïve approach of just dropping the segments didn’t work. Or rather, it worked as intended.
Doing it right
Druid actually distinguishes whether a segment is unavailable (and exists in deep storage only) or whether it is available but not preloaded, which is a new thing in Druid 27. The latter case is expressed by configuring a load rule for that segment, but with a replication factor of 0.
Also worth noting is that at least one segment for the datasource in question has to be preloaded, or else Druid won’t be able to query it at all.
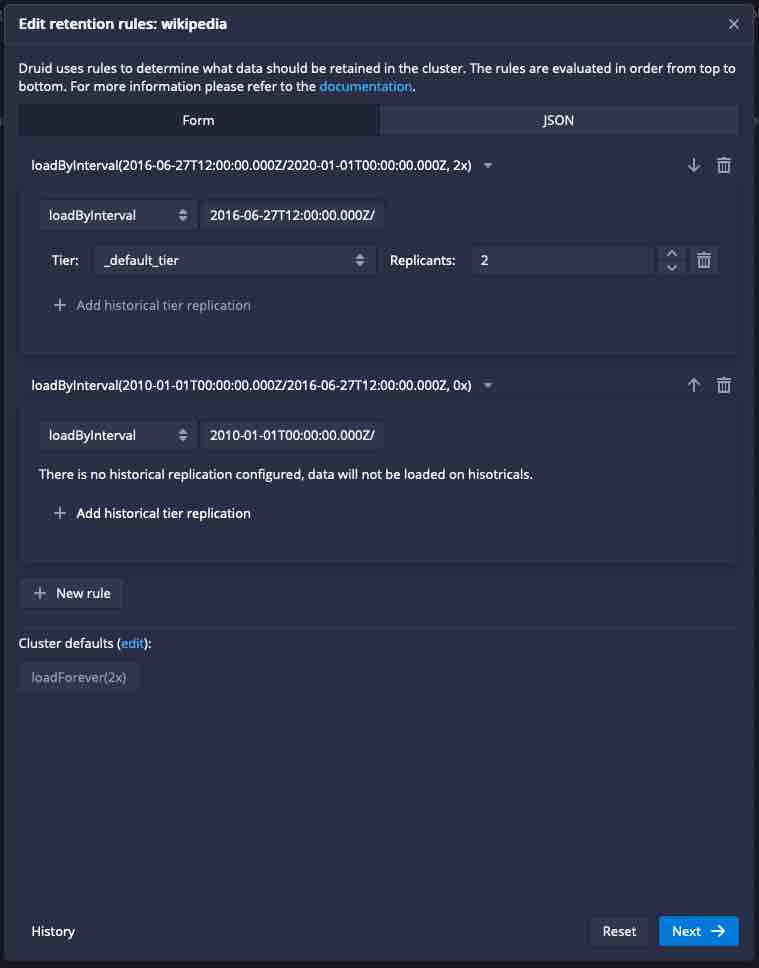
So instead of dropping the segments, let’s load them with a replication factor of 0:
[
{
"interval": "2016-06-27T12:00:00.000Z/2020-01-01T00:00:00.000Z",
"tieredReplicants": {
"_default_tier": 2
},
"useDefaultTierForNull": true,
"type": "loadByInterval"
},
{
"interval": "2010-01-01T00:00:00.000Z/2016-06-27T12:00:00.000Z",
"tieredReplicants": {},
"useDefaultTierForNull": false,
"type": "loadByInterval"
}
]
This is how the rules look like in the console view:
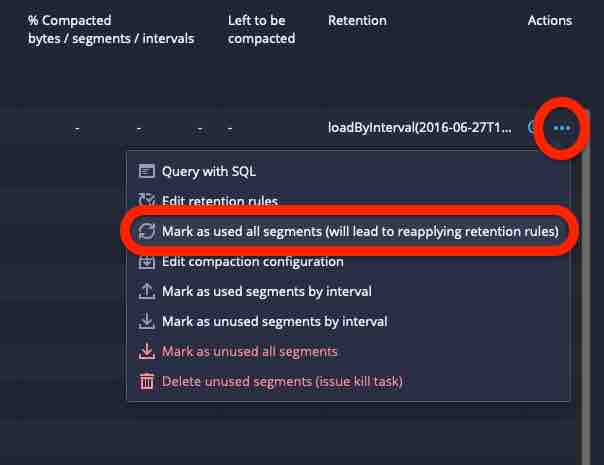
Use the Mark as used all segments function to force the Coordinator to reapply the retention rules:
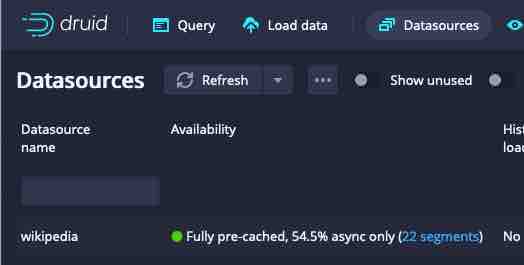
This forces the morning segments to be available for asynchronous query only. You will see this reflected in the Datasources view like this:
Then run the same query again:
curl -L -H 'Content-Type: application/json' localhost:8888/druid/v2/sql/statements -d'{
"query": "SELECT DATE_TRUNC('\''hour'\'', __time), COUNT(*) FROM \"wikipedia\" GROUP BY 1 ORDER BY 1",
"context":{
"executionMode":"ASYNC"
}
}'
{"queryId":"query-7f972571-b26e-4206-a7a8-61503d386d4b","state":"ACCEPTED","createdAt":"2023-09-06T11:38:57.369Z","schema":[{"name":"EXPR$0","type":"TIMESTAMP","nativeType":"LONG"},{"name":"EXPR$1","type":"BIGINT","nativeType":"LONG"}],"durationMs":-1}
This time, the result has 22 rows:
curl -L -H 'Content-Type: application/json' localhost:8888/druid/v2/sql/statements/query-7f972571-b26e-4206-a7a8-61503d386d4b
{"queryId":"query-7f972571-b26e-4206-a7a8-61503d386d4b","state":"SUCCESS","createdAt":"2023-09-06T11:38:57.369Z","schema":[{"name":"EXPR$0","type":"TIMESTAMP","nativeType":"LONG"},{"name":"EXPR$1","type":"BIGINT","nativeType":"LONG"}],"durationMs":14294,"result":{"numTotalRows":22,"totalSizeInBytes":782,"dataSource":"__query_select","sampleRecords":[[1466985600000,876],[1466989200000,870],[1466992800000,960],[1466996400000,1025],[1467000000000,936],[1467003600000,836],[1467007200000,969],[1467010800000,1135],[1467014400000,1141],[1467018000000,1137],[1467021600000,1135],[1467025200000,1115],[1467028800000,1219],[1467032400000,1211],[1467036000000,1353],[1467039600000,1422],[1467043200000,1442],[1467046800000,1339],[1467050400000,1321],[1467054000000,1175],[1467057600000,1213],[1467061200000,603]],"pages":[{"id":0,"numRows":22,"sizeInBytes":782}]}}
We have successfully queried data that partially exists in deep storage only!
Learnings
- Deep storage query is a great new feature that helps organizations to run Druid in a cost effective way, retaining the ability to query large amounts of historical data.
- There is a new API endpoint for queries that include segments from deep storage. These queries run asynchronously.
- You have to configure a load rule with a replication factor of 0 in order to make segments available for deep storage queries.
- At least one segment of a datasource needs to be preloaded on the historical servers in order to run deep storage queries.