Apache Druid: Data Lifecycle Management

One feature that contributes greatly to the performance of Druid is rollup. Rolling up converts a detail table into an aggregate table that contains
- a truncated timestamp: the granularity of that timestamp is known as the query granularity
- a number of dimensions, usually string fields that the data is grouped by
- a number of metrics. These are usually aggregations of numeric fields, but in the case of Druid you could also find data sketches as metrics, such as theta sketches that allow you to get approximate distinct counts out of aggregated data.
Rollup can significantly reduce the amount of storage needed for a dataset and thence the amount of data that needs to be scanned for a query.
Rollup and Data Lifecycle Management
Staggered Rollups
Many of my customers would like to take advantage of the space savings promised by rollup. Their requirement is often like this:
- For a limited period of time, such as the current and last month, keep the data at a relatively detailed level, such as daily or hourly.
- Older data should be aggregated on a monthly level.
Sometimes the requirement is a bit more complex, or staggered:
- Keep daily data for the current month.
- Roll up to weekly data for the last 3 months
- and to monthly data for anything that is older than 3 months.
It is this more complex scenario where lurk some traps for the unwary, which I want to explore today. This tutorial works with the Druid 25.0 quickstart, and I am running Druid on my laptop - for other configurations you would have to adapt the API endpoint accordingly.
How Staggered Rollups Are Done in Druid
Rollups as part of data lifecycle management are executed using compaction tasks in Druid. You can picture a compaction task as a reindexing task where most configuration options are taken 1:1 from the original datasource, and the datasource is reindexed onto itself. If you need only one kind of compaction, you can run it as a so called autocompaction job in the background. But the staggered scenario that we are discussing means, you need to submit those compaction jobs explicitly, via API calls, to the Druid Overlord. A compaction spec is a JSON file, much like an ingestion spec but simpler.
You can submit a compaction task using a little shell script like this:
#!/bin/bash
curl -XPOST -H "Content-Type: application/json" http://localhost:8888/druid/indexer/v1/task -d@$1
The Data
Data Generation
Let’s generate ourselves some data. I want to create a data set with 6 months’ worth of data, 10 records per day, and each record has a random user ID because I want to count unique users as well.
This little Python script does the job:
import random
from datetime import date, timedelta
MAXUSERS = 1000
ROWSPERDAY = 10
def daterange(start_date, end_date):
for n in range(int((end_date - start_date).days)):
yield start_date + timedelta(n)
def main():
start_date = date(2022, 1, 1)
end_date = date(2022, 7, 1)
for single_date in daterange(start_date, end_date):
this_day = single_date.strftime("%Y-%m-%d")
for i in range(ROWSPERDAY):
print(this_day + ",u" + "{:04d}".format(random.randrange(MAXUSERS)))
if __name__ == "__main__":
main()
Run the script and save the output to a file data.csv.
Data Ingestion
Let’s ingest the data. Here is the ingestion spec (edit the file path):
{
"type": "index_parallel",
"spec": {
"dataSchema": {
"dataSource": "user_data",
"timestampSpec": {
"column": "ts",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"dummy1",
"dummy2"
]
},
"metricsSpec": [
{
"type": "count",
"name": "__count"
},
{
"type": "thetaSketch",
"name": "theta_user",
"fieldName": "user",
"size": 16384
},
{
"type": "HLLSketchBuild",
"name": "hll_user",
"fieldName": "user",
"lgK": 12,
"tgtHllType": "HLL_4"
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "DAY",
"rollup": true
},
"transformSpec": {
"transforms": [
{
"type": "expression",
"name": "dummy1",
"expression": "'A'"
},
{
"type": "expression",
"name": "dummy2",
"expression": "'B'"
}
]
}
},
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "local",
"baseDir": "/path/to/file/",
"filter": "data.csv"
},
"inputFormat": {
"type": "csv",
"columns": [
"ts",
"user"
],
"findColumnsFromHeader": false
},
"appendToExisting": false,
"dropExisting": false
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"maxRowsInMemory": 1000000,
"partitionsSpec": {
"type": "range",
"maxRowsPerSegment": 5000000,
"partitionDimensions": [
"dummy1",
"dummy2"
]
},
"forceGuaranteedRollup": true
}
}
}
A few notes:
- I am rolling up by day and also creating daily segments.
- I created two dummy dimensions using transforms. This is so I can enforce range partitioning and make sure it is preserved during my lifecycle management operations.
You can submit the ingestion task using the API call above, or by pasting into the Druid console wizard.
Querying the Data
Let’s first craft a query to verify our data before and after each step. We are going to look at
- the number of rows in our datasource, as an indicator whether the rollup worked
- the sum of the total count of original rows
- the number of unique users,
broken down by month, and as a grand total.
SELECT
CASE WHEN FLOOR(__time TO MONTH) IS NULL THEN NULL ELSE FLOOR(__time TO MONTH) END AS "date",
COUNT(*) AS numRowsCompacted,
SUM(__count) AS numRowsOrig,
THETA_SKETCH_ESTIMATE(DS_THETA(theta_user)) AS uniqueUsersTheta
FROM "user_data"
GROUP BY ROLLUP(1)
The reason for the somewhat awkward incantation around the date expression is explained here.
Note this query down, we will repeat it after every step.
Reference Result
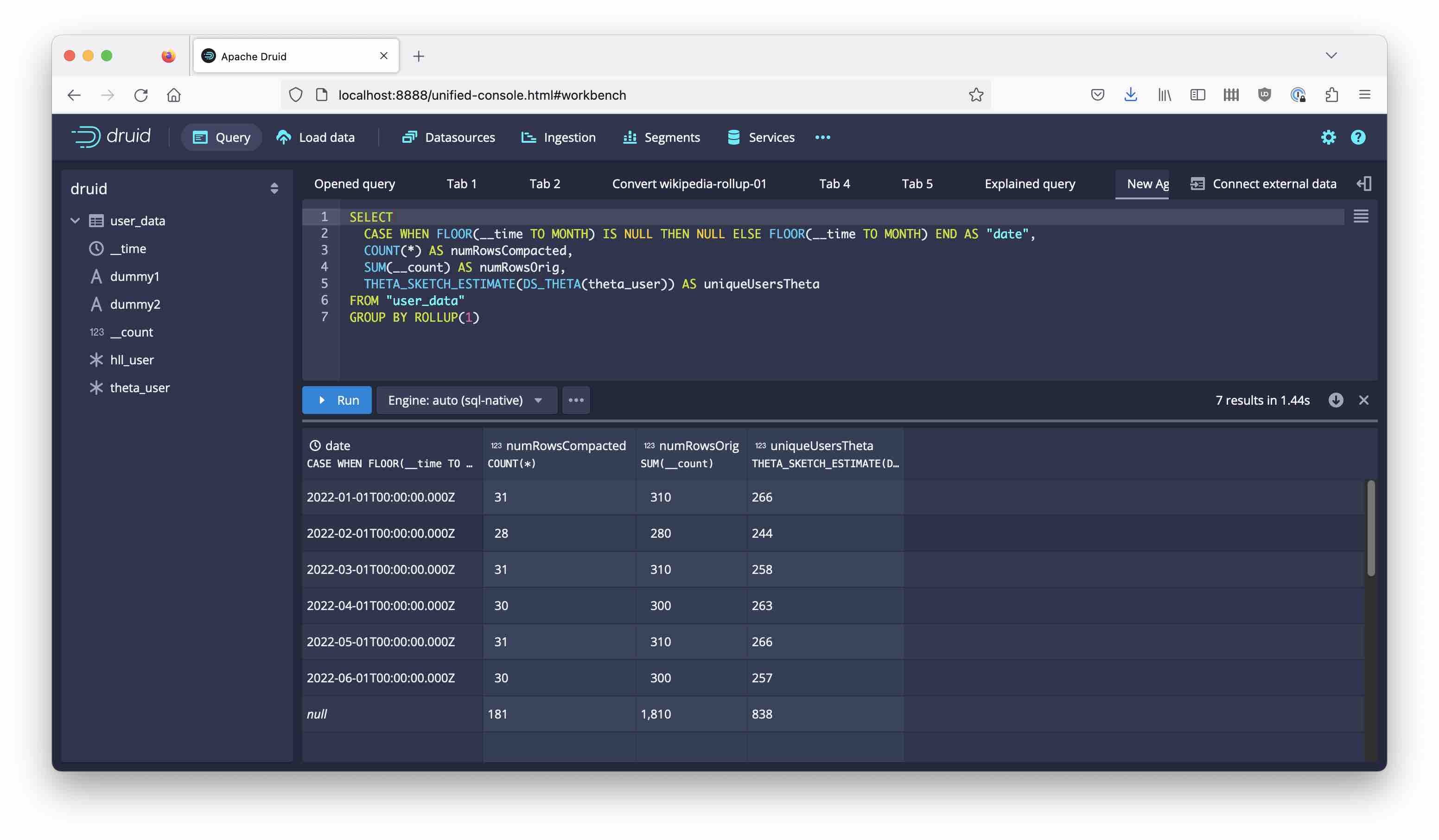
Once the data has been ingested, run the above query. Here’s my result - your unique user counts will likely be different:
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-01-01T00:00:00.000Z | 31 | 310 | 266 |
| 2022-02-01T00:00:00.000Z | 28 | 280 | 244 |
| 2022-03-01T00:00:00.000Z | 31 | 310 | 258 |
| 2022-04-01T00:00:00.000Z | 30 | 300 | 263 |
| 2022-05-01T00:00:00.000Z | 31 | 310 | 266 |
| 2022-06-01T00:00:00.000Z | 30 | 300 | 257 |
| null | 181 | 1810 | 838 |
We have 1810 events, aggregated into 181 database rows. Each month’s event count is 10x the number of days in the month.
Compaction of Older Data
Let’s first implement a simple compaction strategy. All data except the latest month should be rolled up to monthly. Here’s the compaction spec:
{
"type": "compact",
"dataSource": "user_data",
"ioConfig": {
"type": "compact",
"inputSpec": {
"type": "interval",
"interval": "2022-01-01/2022-06-01"
}
},
"granularitySpec": {
"segmentGranularity": "month",
"queryGranularity": "month"
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"maxRowsInMemory": 1000000,
"partitionsSpec": {
"type": "range",
"maxRowsPerSegment": 5000000,
"partitionDimensions": [
"dummy1",
"dummy2"
]
},
"forceGuaranteedRollup": true
}
}
We chose the segment granularity and query granularity both to be month; the tuningConfig section has been copied from the ingestion spec in order to get the same (range) partitioning.
If you do not specify the `tuningConfig -> partitionsSpec`, you will end up with dynamic partitioning, which is usually not what you want.
Submit the compaction task and wait for it to finish. Then run the same query again. Here is my result:
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-01-01T00:00:00.000Z | 1 | 310 | 266 |
| 2022-02-01T00:00:00.000Z | 1 | 280 | 244 |
| 2022-03-01T00:00:00.000Z | 1 | 310 | 258 |
| 2022-04-01T00:00:00.000Z | 1 | 300 | 263 |
| 2022-05-01T00:00:00.000Z | 1 | 310 | 266 |
| 2022-06-01T00:00:00.000Z | 30 | 300 | 257 |
| null | 35 | 1810 | 838 |
The first 5 months have been compacted into one row per month, but the total count of events and the number of unique users are unaffected. (The unique estimate would likely differ slightly for a bigger data set.)
This is what we wanted to achieve doing the rollup. Now let’s look at a more complex, staggered scenario.
Staggered Compaction in Practice
Let’s implement the following compaction scheme:
- The latest month (June in our case) will be left at the current detail level (daily).
- The previous month (May) should be rolled up to weekly granularity.
- All older data should be rolled up to monthly granularity.
1. Restoring the Detail Data
Before you run this test, rerun the original ingestion so we can start with the detail data.
2. First Attempt at Weekly Rollup for May
Let’s roll the May data up to weekly segments with a weekly query granularity.
Submit this compaction spec:
{
"type": "compact",
"dataSource": "user_data",
"ioConfig": {
"type": "compact",
"inputSpec": {
"type": "interval",
"interval": "2022-05-01/2022-06-01"
}
},
"granularitySpec": {
"segmentGranularity": "week",
"queryGranularity": "week"
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"maxRowsInMemory": 1000000,
"partitionsSpec": {
"type": "range",
"maxRowsPerSegment": 5000000,
"partitionDimensions": [
"dummy1",
"dummy2"
]
},
"forceGuaranteedRollup": true
}
}
Run the same query again:
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-01-01T00:00:00.000Z | 31 | 310 | 266 |
| 2022-02-01T00:00:00.000Z | 28 | 280 | 244 |
| 2022-03-01T00:00:00.000Z | 31 | 310 | 258 |
| 2022-04-01T00:00:00.000Z | 25 | 250 | 221 |
| 2022-05-01T00:00:00.000Z | 5 | 300 | 260 |
| 2022-06-01T00:00:00.000Z | 25 | 250 | 215 |
| null | 145 | 1700 | 816 |
This does not look good. As result of our operation, some data in the April and June months seems to have gone missing, also the count for May is not correct, nor is the total count. What happened?
A look at the Segments view explains the problem:
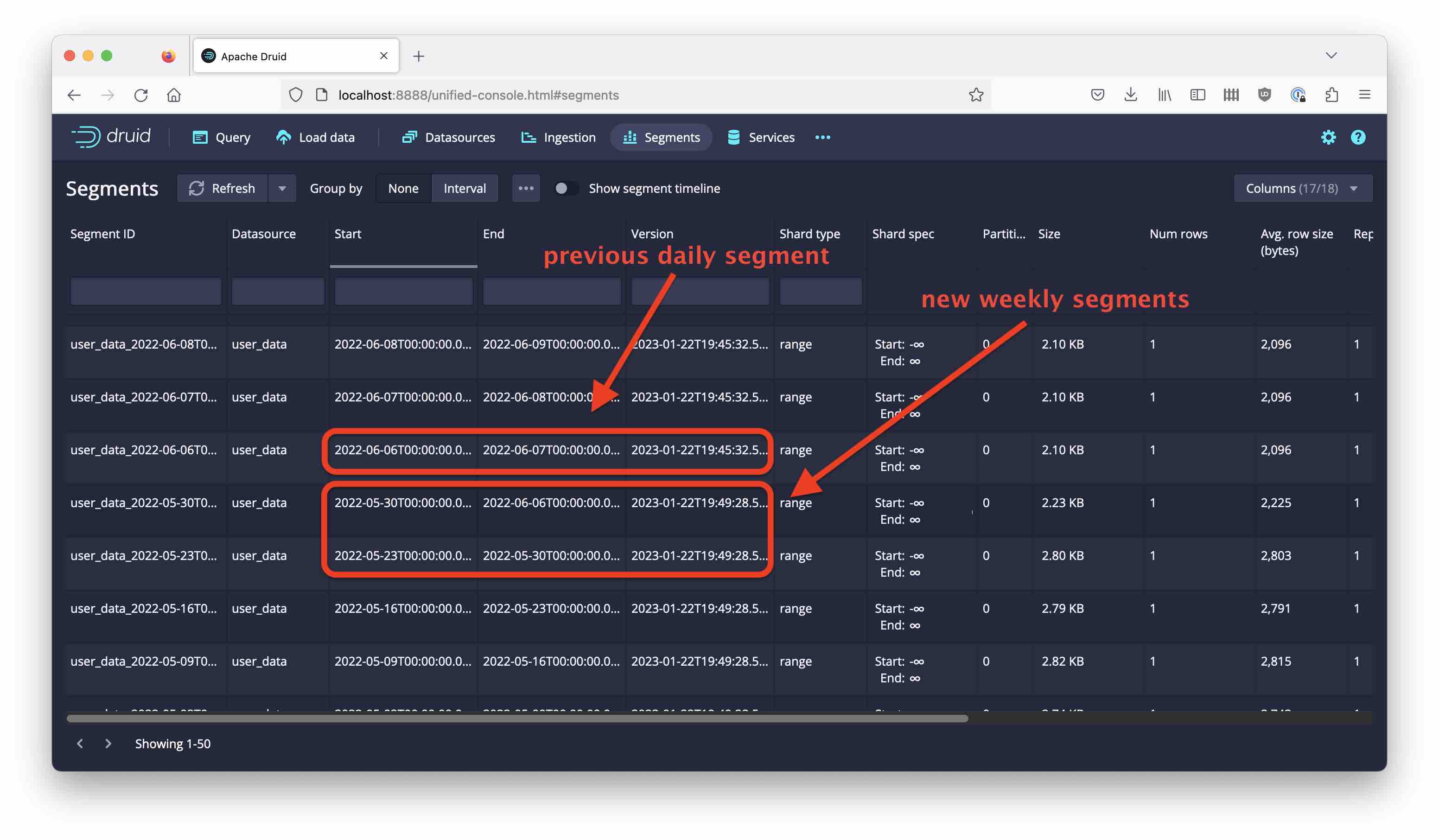
Because calendar weeks don’t align with months, Druid has created segments that extend into the surrounding months. These segments overshadow some of the original data in those months. For instance, we have one segment for the week of 30 May to 5 June. This means all the original data for 1-5 June are invisible now.
Even worse, there’s a segment that has a timestamp (beginning of calendar week) in April, but data from May, and it overshadows the original April data:
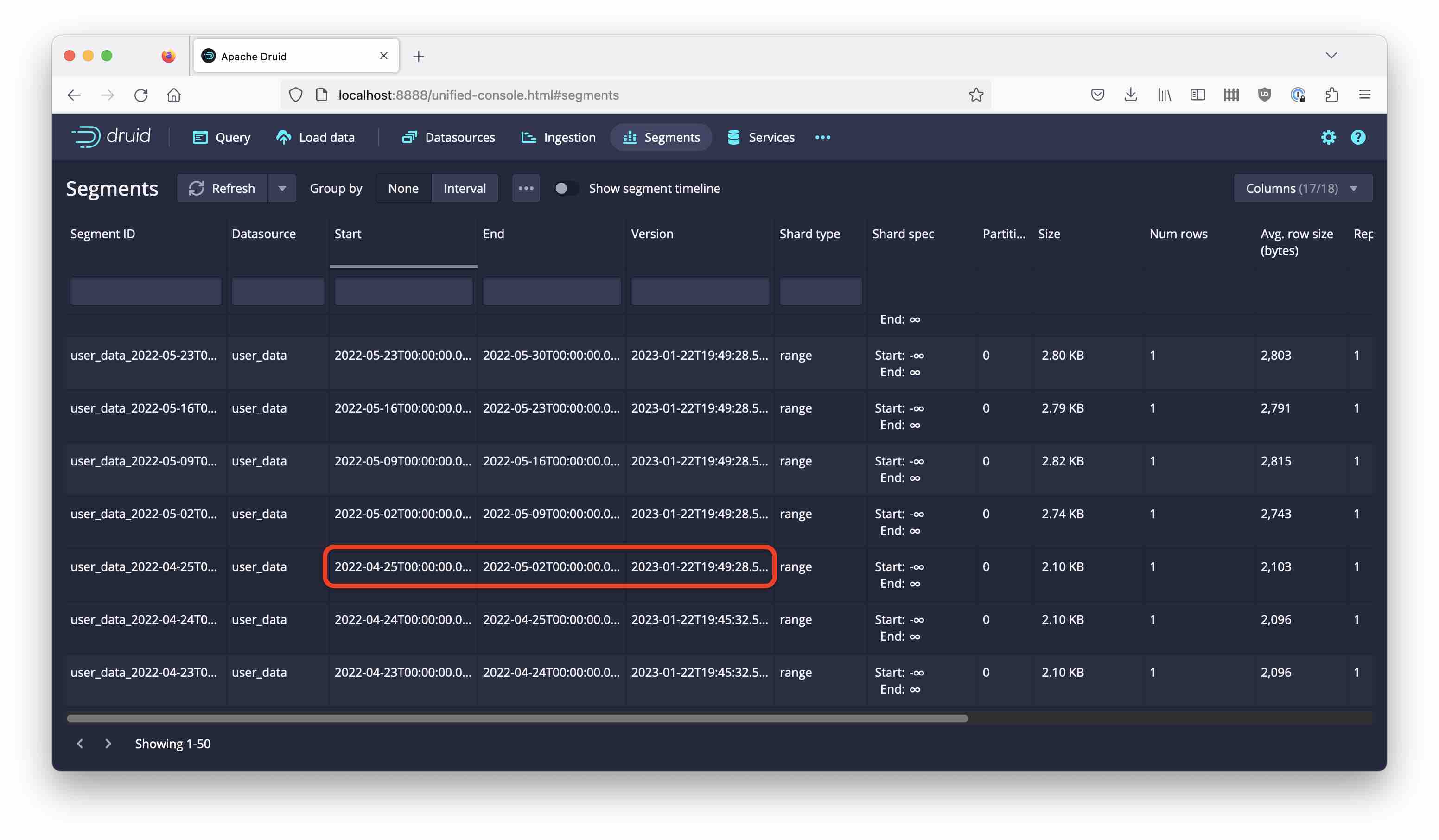
Maybe we can fix the problem by forcing the segment granularity to MONTH?
3. Restoring the Detail Data
Ingest the original data set again.
4. Weekly Rollup with Monthly Segment Granularity
Let’s give it another try. Use the same compaction spec, only changing the segment granularity:
{
"type": "compact",
"dataSource": "user_data",
"ioConfig": {
"type": "compact",
"inputSpec": {
"type": "interval",
"interval": "2022-05-01/2022-06-01"
}
},
"granularitySpec": {
"segmentGranularity": "month",
"queryGranularity": "week"
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"maxRowsInMemory": 1000000,
"partitionsSpec": {
"type": "range",
"maxRowsPerSegment": 5000000,
"partitionDimensions": [
"dummy1",
"dummy2"
]
},
"forceGuaranteedRollup": true
}
}
Submit this spec, and run the reference query again:
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-01-01T00:00:00.000Z | 31 | 310 | 266 |
| 2022-02-01T00:00:00.000Z | 28 | 280 | 244 |
| 2022-03-01T00:00:00.000Z | 31 | 310 | 258 |
| 2022-04-01T00:00:00.000Z | 30 | 300 | 263 |
| 2022-05-01T00:00:00.000Z | 6 | 310 | 266 |
| 2022-06-01T00:00:00.000Z | 30 | 300 | 257 |
| null | 156 | 1810 | 838 |
This time, the results are correct!
Looking at the segments, we see one new segment spanning the whole month of May, surrounded by the older daily segments:
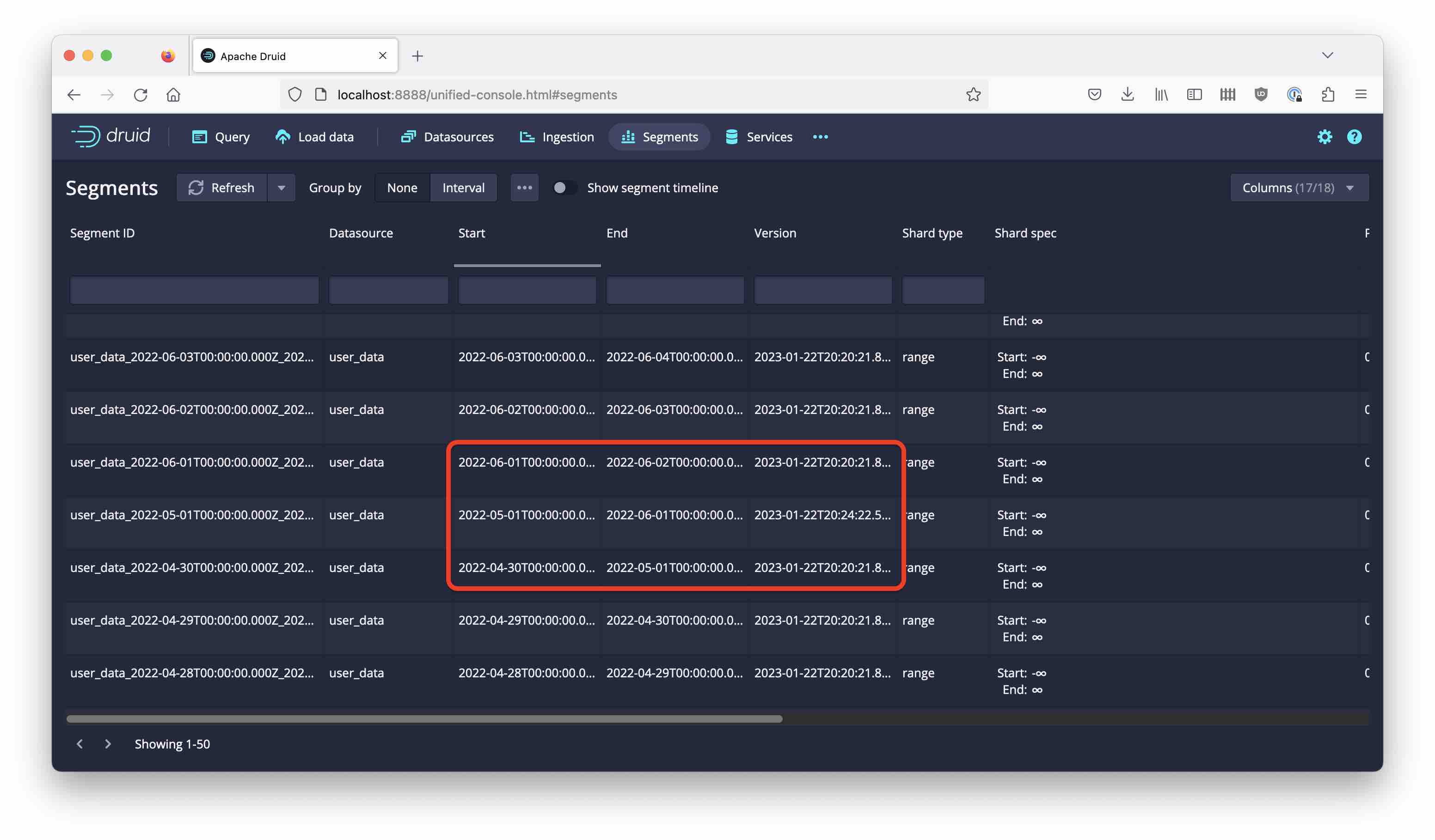
Still, we are left with an open question. If truncating the timestamp to weekly would place some events into April, then why don’t we see the same here?
Let’s run one more query. This time, we want to look at the exact timestamps in the new segments:
SELECT
__time AS "date",
COUNT(*) AS numRowsCompacted,
SUM(__count) AS numRowsOrig,
THETA_SKETCH_ESTIMATE(DS_THETA(theta_user)) AS uniqueUsersTheta
FROM "user_data"
WHERE FLOOR(__time TO MONTH) = TIMESTAMP'2022-05-01'
GROUP BY 1
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-05-01T00:00:00.000Z | 1 | 10 | 10 |
| 2022-05-02T00:00:00.000Z | 1 | 70 | 63 |
| 2022-05-09T00:00:00.000Z | 1 | 70 | 69 |
| 2022-05-16T00:00:00.000Z | 1 | 70 | 67 |
| 2022-05-23T00:00:00.000Z | 1 | 70 | 68 |
| 2022-05-30T00:00:00.000Z | 1 | 20 | 20 |
The timestamp of the records at the beginning of the months has not been truncated all the way down to the beginning of the calendar week, but only to the beginning of the segment! Our data is still good.
If you relied on the precise calendar weeks though, your results would be incorrect. What you should do in such a case is add another FLOOR expression to your query:
SELECT
FLOOR(__time TO WEEK) AS "date",
COUNT(*) AS numRowsCompacted,
SUM(__count) AS numRowsOrig,
THETA_SKETCH_ESTIMATE(DS_THETA(theta_user)) AS uniqueUsersTheta
FROM "user_data"
WHERE FLOOR(__time TO MONTH) = TIMESTAMP'2022-05-01'
GROUP BY 1
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-04-25T00:00:00.000Z | 1 | 10 | 10 |
| 2022-05-02T00:00:00.000Z | 1 | 70 | 63 |
| 2022-05-09T00:00:00.000Z | 1 | 70 | 69 |
| 2022-05-16T00:00:00.000Z | 1 | 70 | 67 |
| 2022-05-23T00:00:00.000Z | 1 | 70 | 68 |
| 2022-05-30T00:00:00.000Z | 1 | 20 | 20 |
This is not really a restriction because you should select the correct timestamp granularity in your queries anyway.
5. Monthly Rollup of Older Data
Let’s proceed to stage 2: rollup of older data. This looks much like the earlier monthly rollup, albeit with a changed interval:
{
"type": "compact",
"dataSource": "user_data",
"ioConfig": {
"type": "compact",
"inputSpec": {
"type": "interval",
"interval": "2022-01-01/2022-05-01"
}
},
"granularitySpec": {
"segmentGranularity": "month",
"queryGranularity": "month"
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"maxRowsInMemory": 1000000,
"partitionsSpec": {
"type": "range",
"maxRowsPerSegment": 5000000,
"partitionDimensions": [
"dummy1",
"dummy2"
]
},
"forceGuaranteedRollup": true
}
}
And the result:
| date | numRowsCompacted | numRowsOrig | uniqueUsersTheta |
|---|---|---|---|
| 2022-01-01T00:00:00.000Z | 1 | 310 | 266 |
| 2022-02-01T00:00:00.000Z | 1 | 280 | 244 |
| 2022-03-01T00:00:00.000Z | 1 | 310 | 258 |
| 2022-04-01T00:00:00.000Z | 1 | 300 | 263 |
| 2022-05-01T00:00:00.000Z | 6 | 310 | 266 |
| 2022-06-01T00:00:00.000Z | 30 | 300 | 257 |
| null | 40 | 1810 | 838 |
We have achieved the desired result. In a production scenario, you would want to automatically generate these compaction specs with the correct time intervals, and have the process controlled by a scheduler.
Conclusion
Data rollup helps a lot in controlling the amount of data in a Druid datasource. It is possible to have multiple stages of rollup as data ages in the system. Rollup is controlled by the query granularity and can be adjusted using compaction tasks.
When staggering multiple stages of rollup, always make sure segment granularities are aligned. When in doubt, use the coarsest segment granularity for all stages:
- If segment granularity is not aligned between stages of compaction, compaction tasks can lead to data loss.
- If segment granularity is not aligned with query granularity, the result of timestamp truncation might sometimes be unexpected because the minimum timestamp that can result is governed by segment granularity, not query granularity. However, this can be mitigated by using another
FLOORphrase during query time.
In your compaction spec, do specify the tuningConfig -> partitionsSpec - otherwise Druid will fall back to dynamic partitioning.